




pandasのよく使うコマンドまとめ
pythonライブラリのpandasのよく使うコマンドをまとめました。基礎的なものばかりですが、コマンドをよく忘れてしまうため、チートシート目的です。
pandasを利用するにあたって、事前に macターミナル: pip3 install pandas 、 windowsコマンドプロンプト: pip install pandas でpandasライブラリのインストールが必要です。
目次
-

DataFrameを生成/出力
-

DataFrameのデータを検索/調査/確認
-
DataFrameを整形
-

DataFrameのデータを変更
-

DataFrameの計算
DataFrameを作成/出力
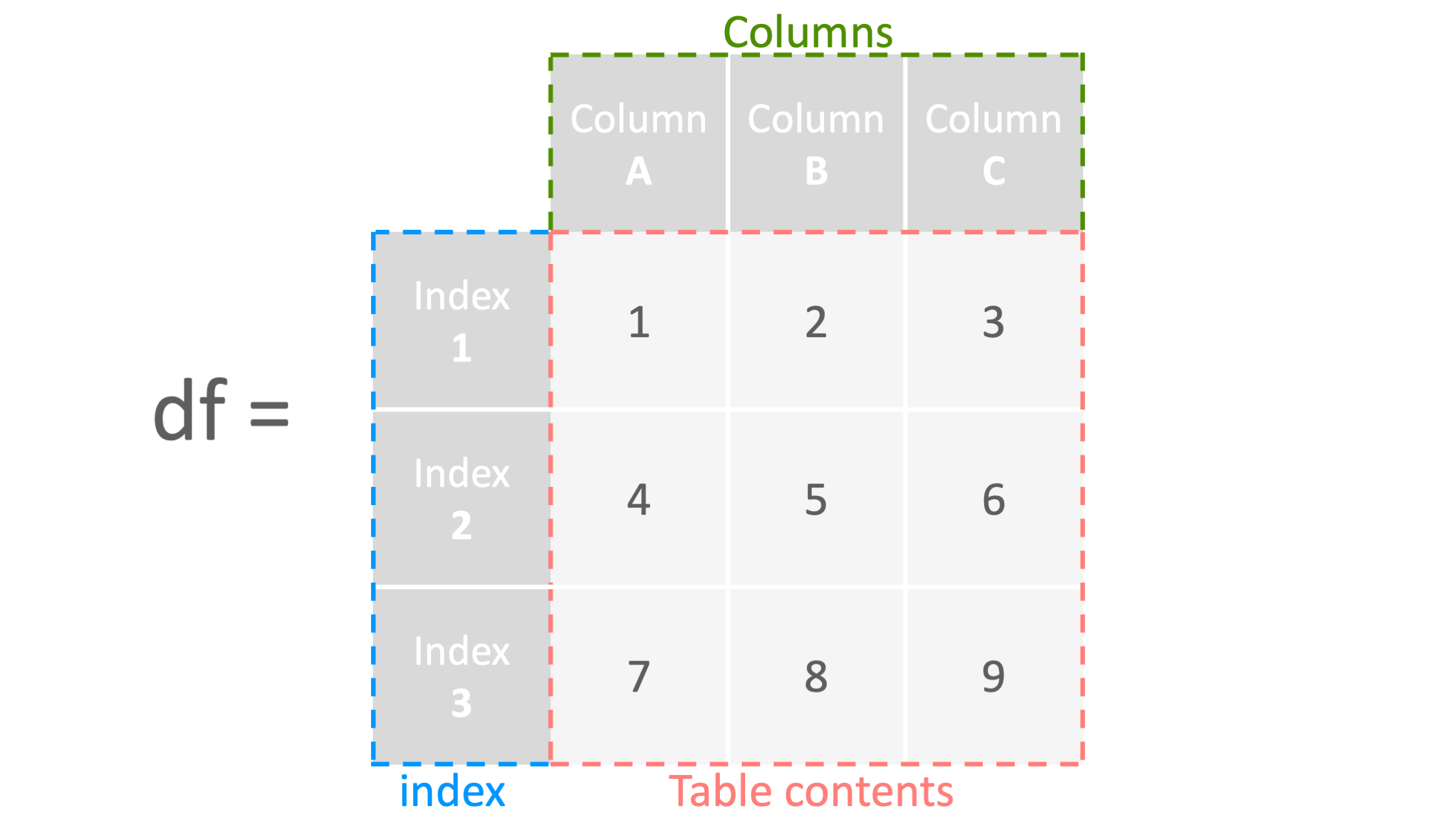
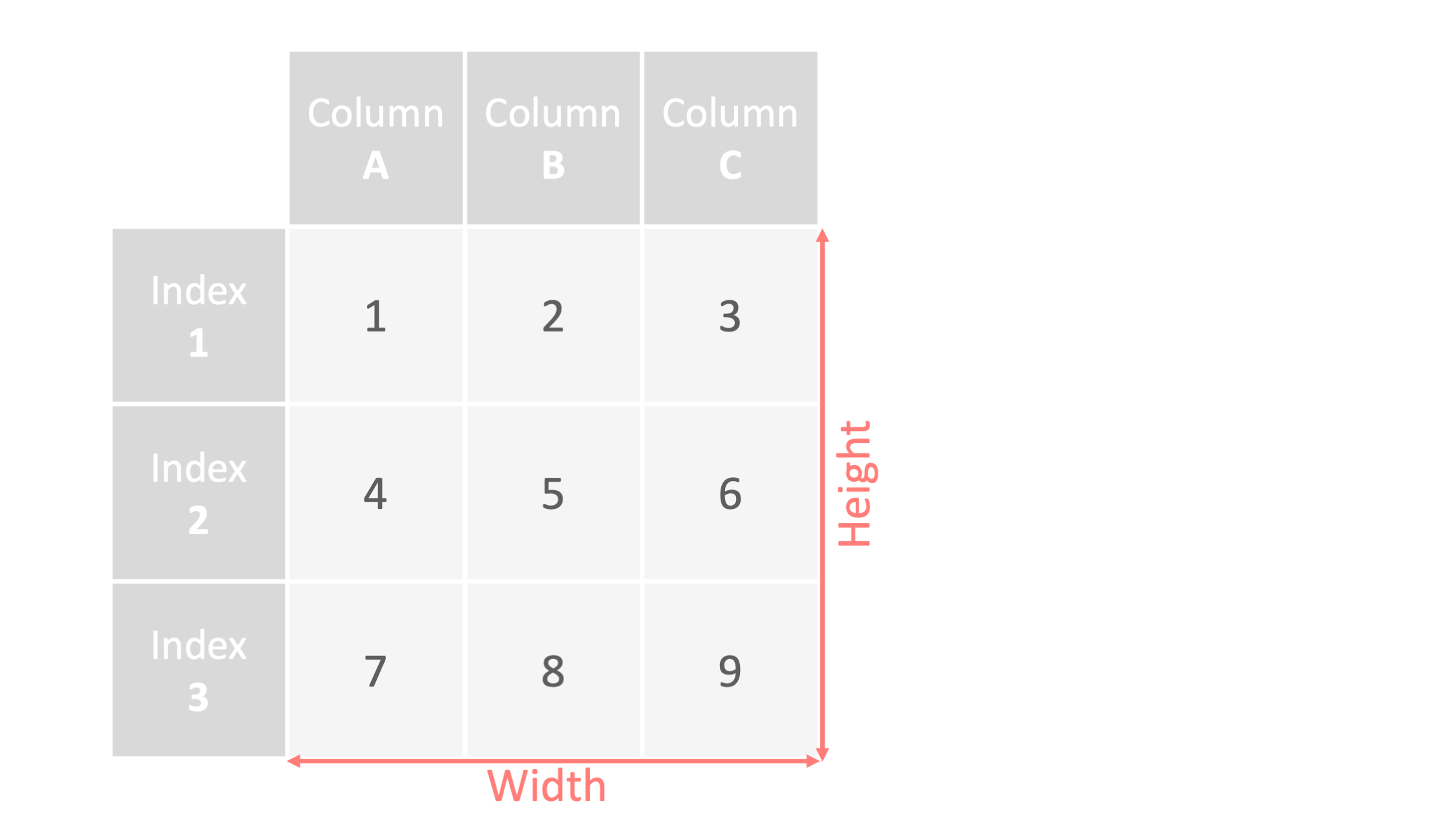
DataFrameの生成
command
df=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],
index=["index1", "index2", "index3"],
columns=["columnA", "columnB", "columnC"])
index=["index1", "index2", "index3"],
columns=["columnA", "columnB", "columnC"])
<- 配列の中身
<- インデックス名
<- 列名
<- インデックス名
<- 列名
df=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]]①,
index=["index1", "index2", "index3"]②,
columns=["columnA", "columnB", "columnC"]③)
index=["index1", "index2", "index3"]②,
columns=["columnA", "columnB", "columnC"]③)
① 配列の中身
② インデックス名
③ 列名
② インデックス名
③ 列名
例1: 2次元構造のDataFrame ▽
import pandas as pd
df=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],
index=["index1", "index2", "index3"], #indexは指定しなくても可
columns=["columnA", "columnB", "columnC"]) #columnsは指定しなくても可
print(df)
columnA
columnB
columnC
index1
1
2
3
index2
4
5
6
index3
7
8
9
例2: 1次元構造のDataFrame ▽
import pandas as pd
df=pd.DataFrame([1, 2, 3],
index=["index1", "index2", "index3"], #indexは指定しなくても可
columns=["columnA"]) #columnsは指定しなくても可
print(df)
columnA
index1
1
index2
2
index3
3
CSV,TSVをDataFrameへ取り込み
command
df=pd.read_csv("data.csv",
sep="\t",
encoding="shift-jis")
sep="\t",
encoding="shift-jis")
<- 読み込むファイル名(ファイルパス)
<- 区切り文字(csv読み込みは設定不要でtsvでは"\t")
<- 文字コード指定(読み込みファイルが”UTF-8”以外の場合)
<- 区切り文字(csv読み込みは設定不要でtsvでは"\t")
<- 文字コード指定(読み込みファイルが”UTF-8”以外の場合)
df=pd.read_csv("data.csv",①,
sep="\t"②,
columns=encoding="shift-jis"③)
sep="\t"②,
columns=encoding="shift-jis"③)
① 読み込むファイル名(ファイルパス)
② 区切り文字(csv読み込みは設定不要でtsvでは"\t")
③ 文字コード指定(読み込みファイルが”UTF-8”以外の場合)
② 区切り文字(csv読み込みは設定不要でtsvでは"\t")
③ 文字コード指定(読み込みファイルが”UTF-8”以外の場合)
*取り込むデータの1行目を自動的に列名として取り込むことに注意(対策は以下例を参照)

例1-1: 列名がないCSV ▽
import pandas as pd
#### 取り込むデータの1行目が列名でない場合 ####
"""取り込む data.csv の中身
1,2,3
4,5,6
7,8,9
"""
df1=pd.read_csv("data.csv", header=None) #CSVデータの1行目がデータの場合は、header=Noneを指定
print("df1=", df1)
#### 取り込むデータの1行目が列名である場合 ####
"""取り込むdata.csv の中身
columnA,columnB,columnC
1,2,3
4,5,6
7,8,9
"""
df2=pd.read_csv("data.csv")
print("df2=", df2)
fd1=
0
1
2
0
1
2
3
1
4
5
6
2
7
8
9
df2=
columnA
columnB
columnC
0
1
2
3
1
4
5
6
2
7
8
9
例1-2: 列名をつける場合 ▽
import pandas as pd
#### 列名が無いデータに列名を付け加える場合 ####
"""取り込むdata.csv の中身
1,2,3
4,5,6
7,8,9
"""
df=pd.read_csv("data.csv",
names=("columnA", "columnB", "columnC")) #namesで列名を指定する
print("df=", df)
df=
columnA
columnB
columnC
0
1
2
3
1
4
5
6
2
7
8
9
例1-3: インデックスがあるCSV ▽
import pandas as pd
#### 読み込むデータの1列目がインデックスの場合 ####
"""取り込むdata1.csv の中身
,columnA, columnB, columnC
index1,1,2,3
index2,4,5,6
index3,7,8,9
"""
df1=pd.read_csv("data1.csv",
index_col=0) #index_colでインデックスとする列を指定する
print("df1=", df1)
#列名となる1行目のデータ数が2行目以降より少ない場合は、差分がインデックスとなる
"""取り込むdata2.csv の中身
columnA, columnB
index1,1,2,3
index2,4,5,6
index3,7,8,9
"""
df2=pd.read_csv("data2.csv") #index_colを指定しないことに注意
print("df2=", df2)
df1=
columnA
columnB
columnC
index1
1
2
3
index2
4
5
6
index3
7
8
9
df2=
columnA
columnB
index1
1
2
3
index2
4
5
6
index3
7
8
9
例2: TSVの取り込み ▽
import pandas as pd
#### 読み込むデータがtsv形式の場合 ####
"""取り込むdata.tsv の中身
columnA columnB columnC
1 2 3
4 5 6
7 8 9
"""
df1=pd.read_csv("data.tsv",
sep="\t")
print("df1=", df1)
# sep="\t"を指定しないとうまく読み込まれない
df2=pd.read_csv("data.tsv")
print("df2=", df2)
df1=
columnA
columnB
columnC
0
1
2
3
1
4
5
6
2
7
8
9
# sep="\t"を指定しない場合
df2=
columnA\tcolumnB\tcolumnC
0,1\t2\t3
1,4\t5\t6
2,7\t8\t9
例3: 文字コードを指定 ▽
import pandas as pd
#### 読み込むデータの文字コードがUTF-8以外の場合 ####
df=pd.read_csv("data_shift_jis.csv",
encoding="shift-jis")
print("df=", df)
# encodingを指定しないとエラーとなり読み込まれない
df=pd.read_csv("data_shift_jis.csv")
df=
columnA
columnB
columnC
0
あ
い
う
1
え
お
か
2
き
く
け
# encodingを指定しない場合
UnicodeDecodeError ~~~~~
jsonをDataFrameへ取り込み
command
df=pd.read_json("data.json")
<- 読み込むファイル名(ファイルパス)
df=pd.read_json("data.json")
読み込むファイル名(ファイルパス)

例1: jsonファイルの読み込み ▽
import pandas as pd
#### json形式のデータを読み込む ####
"""取り込む data.json の中身
[{"columnA":1,"columnB":2,"columnC":3},
{"columnA":4,"columnB":5,"columnC":6},
{"columnA":7,"columnB":8,"columnC":9}]
"""
df = pd.read_json("data.json")
print("df=", df)
df=
columnA
columnB
columnC
0
1
2
3
1
4
5
6
2
7
8
9
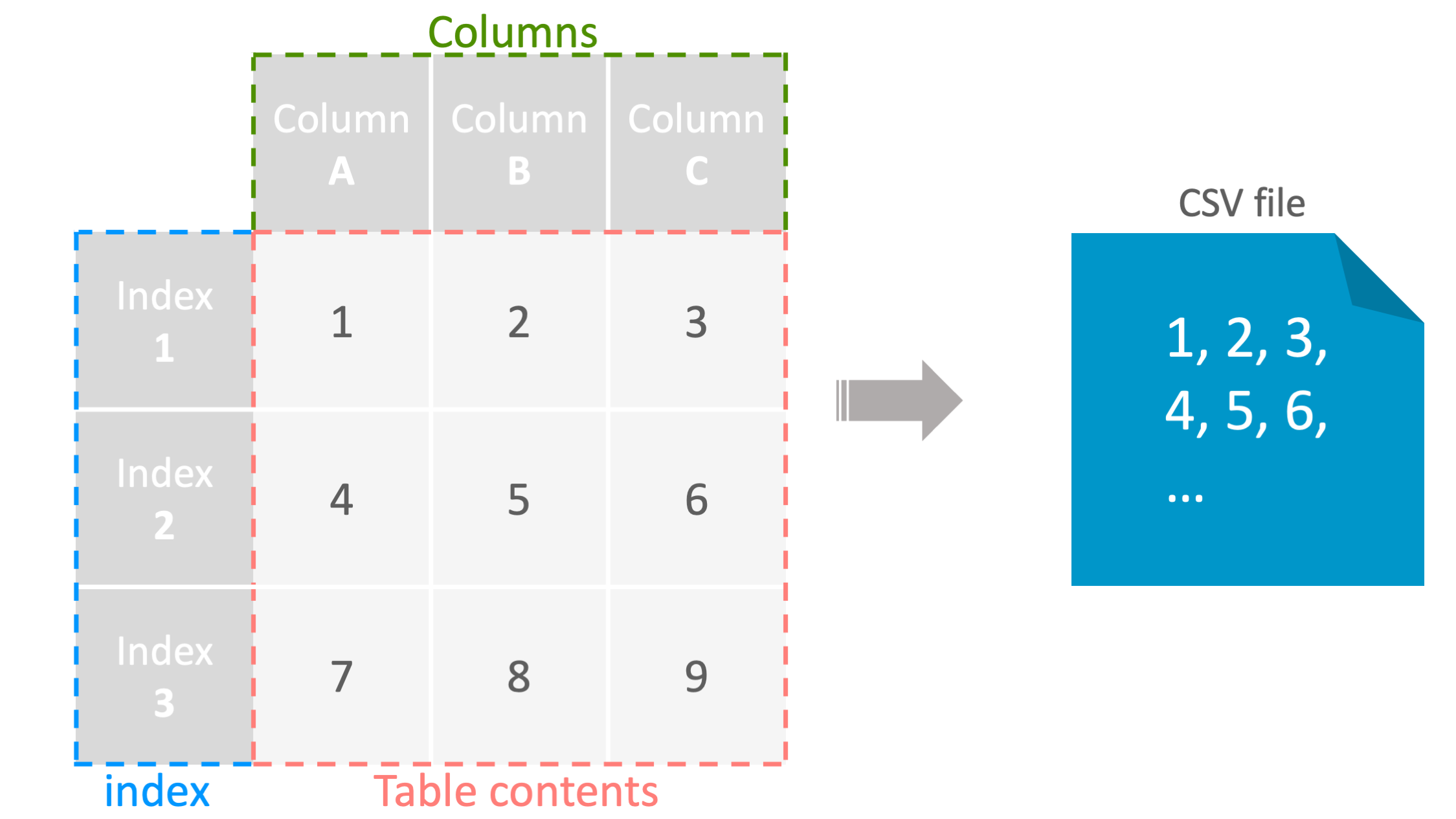
DataFrameをCSV形式で出力
command
df.to_csv("data.csv",
index=False,
header=False)
index=False,
header=False)
<- 出力するファイル名(ファイルパス)
<- インデックスを削除する場合にFalse
<- 列名を削除する場合にFalse
<- インデックスを削除する場合にFalse
<- 列名を削除する場合にFalse
df.to_csv("data.csv",①,
index=False②,
header=False③)
index=False②,
header=False③)
① 出力するファイル名(ファイルパス)
② インデックスを削除する場合にFalse
③ 列名を削除する場合にFalse
② インデックスを削除する場合にFalse
③ 列名を削除する場合にFalse
例1: CSVデータ出力 ▽
import pandas as pd
#### データフレームをCSV形式で出力する ####
"""取り込むdata.csv の中身
,columnA, columnB, columnC
index1,1,2,3
index2,4,5,6
index3,7,8,9
"""
df=pd.DataFrame("data.csv", index_col=0)
# インデックス、列名をつけてCSV出力
df.to_csv("data1.csv")
# インデックスを除いてCSV出力
df.to_csv("data2.csv", index=False)
# 列名を除いてCSV出力
df.to_csv("data3.csv", header=False)
#列名をつけて出力されたCSV
"""data1.csvの中身
,columnA,columnB,columnC
index1,1,2,3
index2,4,5,6
index3,7,8,9
"""
#インデックスを除いて出力されたCSV
"""data2.csvの中身
,columnA,columnB,columnC
1,2,3
4,5,6
7,8,9
"""
#列名を除いて出力されたCSV
"""data3.csvの中身
index1,1,2,3
index2,4,5,6
index3,7,8,9
"""
DataFrameを検索/調査/確認
DataFrameの行数・列数確認
command
df.shape
<- (行数、列数)で出力
df.shape
(行数、列数)で出力
例1: 行数・列数の確認 ▽
import pandas as pd
#### 行数・列数を調べる (DataFrameの形状を調べる) ####
"""取り込むdata.csv の中身
,columnA, columnB, columnC
index1,1,2,3
index2,4,5,6
index3,7,8,9
index4,10,11,12
"""
df=pd.DataFrame("data.csv",index_col=0)
print("df=", df.shape)
df= (4, 3) <- (行数, 列数)
DataFrameのインデックスや列名参照
command
df.index
df.columns
df.columns
<- インデックスの参照
<- 列名の参照
<- 列名の参照
df.index①
df.columns②
df.columns②
① インデックスの参照
② 列名の参照
② 列名の参照
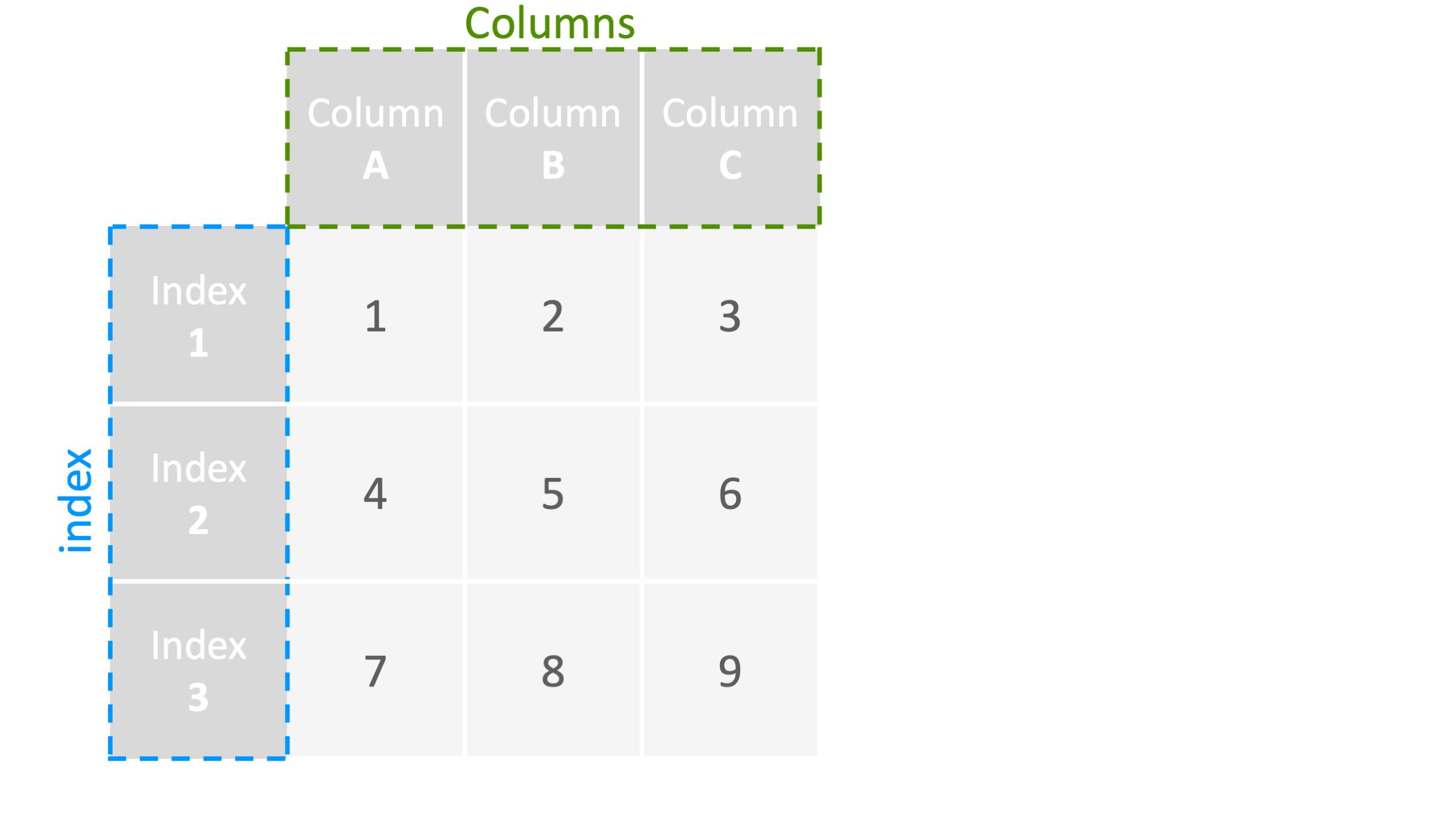
例1: インデックス・列名の確認 ▽
import pandas as pd
#### インデックス・列名の確認 ####
"""取り込むdata.csv の中身
,columnA, columnB, columnC
index1,1,2,3
index2,4,5,6
index3,7,8,9
index4,10,11,12
"""
df=pd.DataFrame("data.csv",index_col=0)
#インデックスの確認
print("index=", df.index)
#列名の確認
print("columns=", df.columns)
#インデックス
index= Index(['index1', 'index2', 'index3', 'index4'], dtype='object')
#列名
columns= Index(['columnA', 'columnB', 'columnC'], dtype='object')
DataFrameの先頭・末尾データ参照
command
df.head(5)
df.tail(5)
df.tail(5)
<- 先頭から括弧内の数字分のデータを表示(デフォルトでは5データ分)
<- 末尾から括弧内の数字分のデータを表示(デフォルトでは5データ分)
<- 末尾から括弧内の数字分のデータを表示(デフォルトでは5データ分)
df.head(5)①
df.tail(5)②
df.tail(5)②
① 先頭から括弧内の数字分のデータを表示(デフォルトでは5データ分)
② 末尾から括弧内の数字分のデータを表示(デフォルトでは5データ分)
② 末尾から括弧内の数字分のデータを表示(デフォルトでは5データ分)
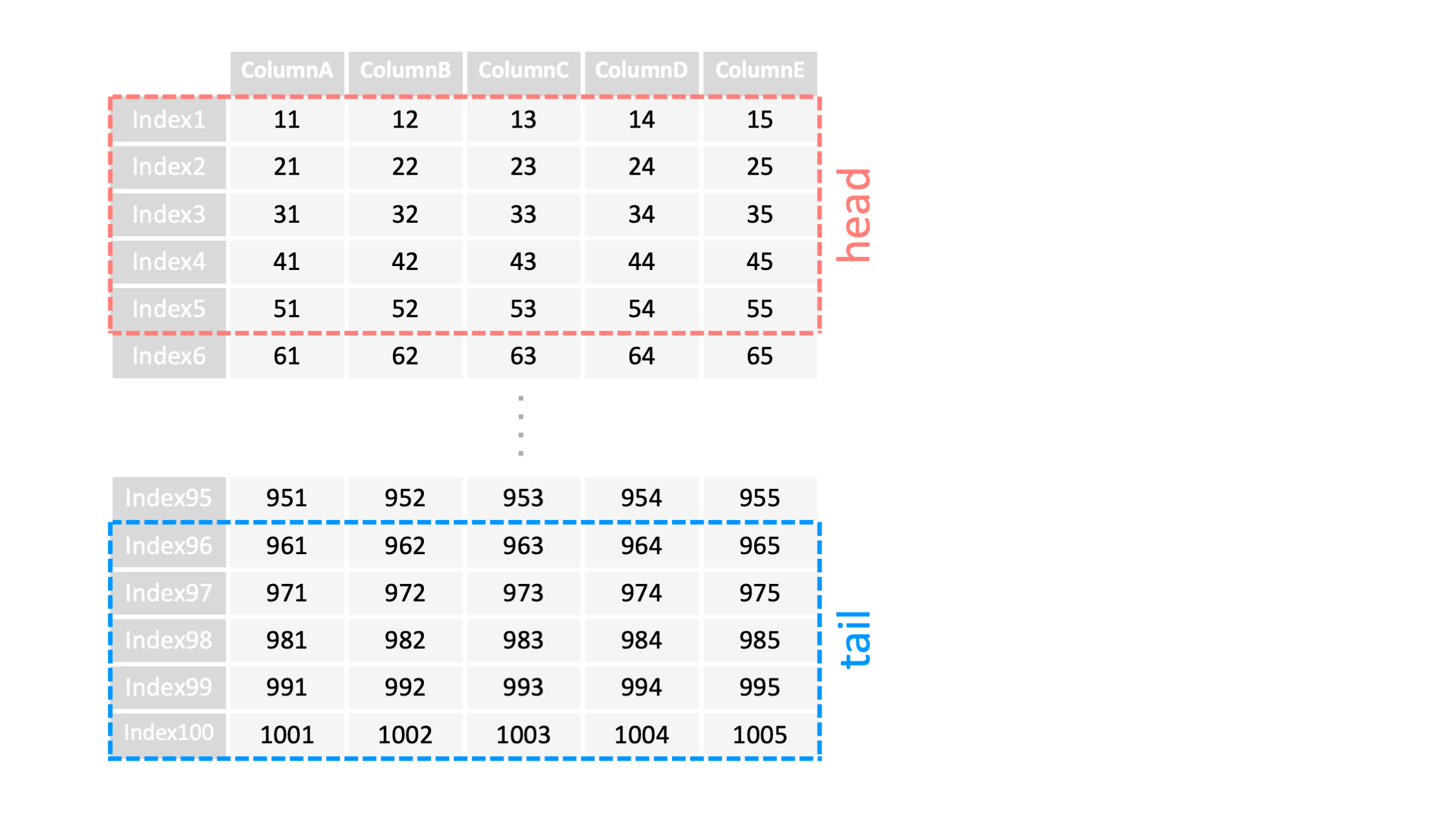
例1: 先頭・末尾データの確認 ▽
import pandas as pd
#### 先頭・末尾データを確認する ####
"""取り込むdata.csv の中身
columnA,columnB,columnC
1,2,3
4,5,6
7,8,9
10,11,12
‥ ‥ ‥
‥ ‥ ‥
49,50,51
52,53,54
55,56,57
58,59,60
"""
df=pd.DataFrame("data.csv")
# 先頭5行を確認
print("df.head()=")
df.head()
# 末尾5行を確認
print("df.tail()=")
df.tail()
df.head()=
columnA
columnB
columnC
0
1
2
3
1
4
5
6
2
7
8
9
3
10
11
12
4
13
14
15
df.tail()=
columnA
columnB
columnC
15
46
47
48
16
49
50
51
17
52
53
54
18
55
56
57
19
58
59
60
DataFrameの列を参照
command
df["ColumnA"]
df[["ColumnC","ColumnD","ColumnE"]]
df[["ColumnC","ColumnD","ColumnE"]]
<- 1列分を参照
<- 2列以上を参照
<- 2列以上を参照
*1列だけを参照する場合と、2列以上参照する場合で、データ型が異なるため"["と"]"の数が異なることに注意
df["ColumnA"]①
df[["ColumnC","ColumnD","ColumnE"]]②
df[["ColumnC","ColumnD","ColumnE"]]②
① 1列分を参照
② 2列以上を参照
② 2列以上を参照
*1列だけを参照する場合と、2列以上参照する場合で、データ型が異なるため"["と"]"の数が異なることに注意

例1: Dataframeを列毎に確認 ▽
import pandas as pd
#### 列毎にDataFrameの値を参照する ####
"""取り込むdata.csv の中身
,columnA,columnB,columnC,columnD,columnE
index1,11,12,13,14,15
index2,21,22,23,24,25
index3,31,32,33,34,35
index4,41,42,43,44,45
index5,51,52,53,54,55
‥ ‥ ‥
‥ ‥ ‥
index96,961,962,963,964,965
index97,971,972,973,974,975
index98,981,982,983,984,985
index99,991,992,993,994,995
index100,1001,1002,1003,1004,1005
"""
df = pd.read_csv("data.csv", index_col=0)
# 1列分を参照
print("columnA=", df["columnA"])
# 3列分を参照
print("columnC-E=", df[["columnC", "columnD", "columnE"]])
columnA=
columnA
index1
11
index2
21
index3
31
index4
41
index5
51
‥
‥
index96
961
index97
971
index98
981
index99
991
index100
1001
Name: columnA, Length: 100, dtype: int64
columnC-E=
columnC
columnD
columnE
index1
13
14
15
index2
23
24
25
index3
33
34
35
index4
43
44
45
index5
53
54
55
‥
‥
index96
963
964
965
index97
973
974
975
index98
983
984
985
index99
993
994
995
index100
1003
1004
1005
100 rows × 3 columns
条件によるDataFrameの行の検索
command
df[df["columnC"] < 40]
df.query("columnC < 40")
df[(df["columnC"] < 40) | (df["columnE"] > 990)]
df.query("columnC < 40 | columnE < 90")
df.query("columnC < 40")
df[(df["columnC"] < 40) | (df["columnE"] > 990)]
df.query("columnC < 40 | columnE < 90")
<- 参照する条件が1つの場合
<- 上記をqueryメソッドを使った場合
<- 参照する条件が複数の場合
<- 上記をqueryメソッドを使った場合
<- 上記をqueryメソッドを使った場合
<- 参照する条件が複数の場合
<- 上記をqueryメソッドを使った場合
df[df["columnC"] < 40]①
df.query("columnC < 40")①'>
df[(df["columnC"] < 40) | (df["columnE"] > 990)]②
df.query("columnC < 40 | columnE < 90")②'
df.query("columnC < 40")①'>
df[(df["columnC"] < 40) | (df["columnE"] > 990)]②
df.query("columnC < 40 | columnE < 90")②'
① 参照する条件が1つの場合
①' ①をqueryメソッドを使った場合
② 参照する条件が複数の場合
②' ②をqueryメソッドを使った場合
①' ①をqueryメソッドを使った場合
② 参照する条件が複数の場合
②' ②をqueryメソッドを使った場合

例1: 参照する条件が1つの場合 ▽
import pandas as pd
#### 指定した条件にマッチしたデータを確認する ####
"""取り込むdata.csvの中身
,columnA,columnB,columnC,columnD,columnE
index1,11,12,13,14,15
index2,21,22,23,24,25
index3,31,32,33,34,35
index4,41,42,43,44,45
index5,51,52,53,54,55
... ... ... ... ... ...
index96,961,962,963,964,965
index97,971,972,973,974,975
index98,981,982,983,984,985
index99,991,992,993,994,995
index100,1001,1002,1003,1004,1005
"""
df = pd.read_csv("data.csv", index_col=0)
#C列の値が40未満となる行を抜き出す
df[df["columnC"]<40]
#df.query("columnC<40")でもOK
#D列の値が984となる行を抜き出す
df[df["columnD"]==984] #df.query("columnD == 984")でもOK
#C列の値が40未満となるデータ
columnA
columnB
columnC
columnD
columnE
index1
11
12
13
14
15
index2
21
22
23
24
25
index3
31
32
33
34
35
#D列の値が984となる行を抜き出す
columnA
columnB
columnC
columnD
columnE
index98
981
982
983
984
985
例2: 参照する条件が複数の場合 ▽
import pandas as pd
#### 指定した条件にマッチしたデータを確認する ####
"""取り込むdata.csvの中身
,columnA,columnB,columnC,columnD,columnE
index1,11,12,13,14,15
index2,21,22,23,24,25
index3,31,32,33,34,35
index4,41,42,43,44,45
index5,51,52,53,54,55
... ... ... ... ... ...
index96,961,962,963,964,965
index97,971,972,973,974,975
index98,981,982,983,984,985
index99,991,992,993,994,995
index100,1001,1002,1003,1004,1005
"""
df = pd.read_csv("data.csv", index_col=0)
#C列の値が40未満 または E列の値が990より大きいデータを抜き出す
df[(df["columnC"]<40)|(df["columnE"]>990)] #df.query("columnC<40 | columnE>990")でもOK
#A列の値が200未満 かつ C列の値が140より大きいデータを抜き出す
df[(df["columnA"]<200)&(df["columnC"]>140)] #df.query("columnA<200 & columnC>140")でもOK
#C列の値が40未満 または E列の値が990より大きいデータ
columnA
columnB
columnC
columnD
columnE
index1
11
12
13
14
15
index2
21
22
23
24
25
index3
31
32
33
34
35
index99
991
992
993
994
995
index100
1001
1002
1003
1004
1005
#A列の値が200未満 かつ C列の値が140より大きいデータ
columnA
columnB
columnC
columnD
columnE
index14
141
142
143
144
145
index15
151
152
153
154
155
index16
161
162
163
164
165
index17
171
172
173
174
175
index18
181
182
183
184
185
index19
191
192
193
194
195
例3: query()の条件式で変数を使う場合 ▽
import pandas as pd
#### 指定した条件にマッチしたデータを確認する ####
"""取り込むdata.csvの中身
,columnA,columnB,columnC
index1,1,2,3
index2,4,5,6
index3,7,8,9
"""
df = pd.read_csv("data.csv", index_col=0)
検索する条件を変数で用意する
x=5
# query()メソッドの条件式で変数を利用する場合、変数の前に@をつける
df.query("columnB==@x")
#B列の値が5となるデータを確認する
columnA
columnB
columnC
index2
4
5
6
例4: query()の条件式で文字列を使う場合 ▽
import pandas as pd
#### 指定した条件にマッチしたデータを確認する ####
"""取り込むdata.csvの中身
,columnA,columnB,columnC
index1,1,2,3
index2,"A","B","C"
index3,4,5,6
"""
df = pd.read_csv("data.csv", index_col=0)
# query()メソッドの条件式で文字列を利用する場合、ダブルクォーテーション " と シングルクォーテーション ' の使い分けに注意する
df.query("columnB=='B'")
#B列の値が5となるデータを確認する
columnA
columnB
columnC
index2
A
B
C
DataFrameのデータ出現数の確認
command
df["columnA"].value_counts()
df["columnA"].value_counts()
*複数行を同時に集計することはできないことに注意
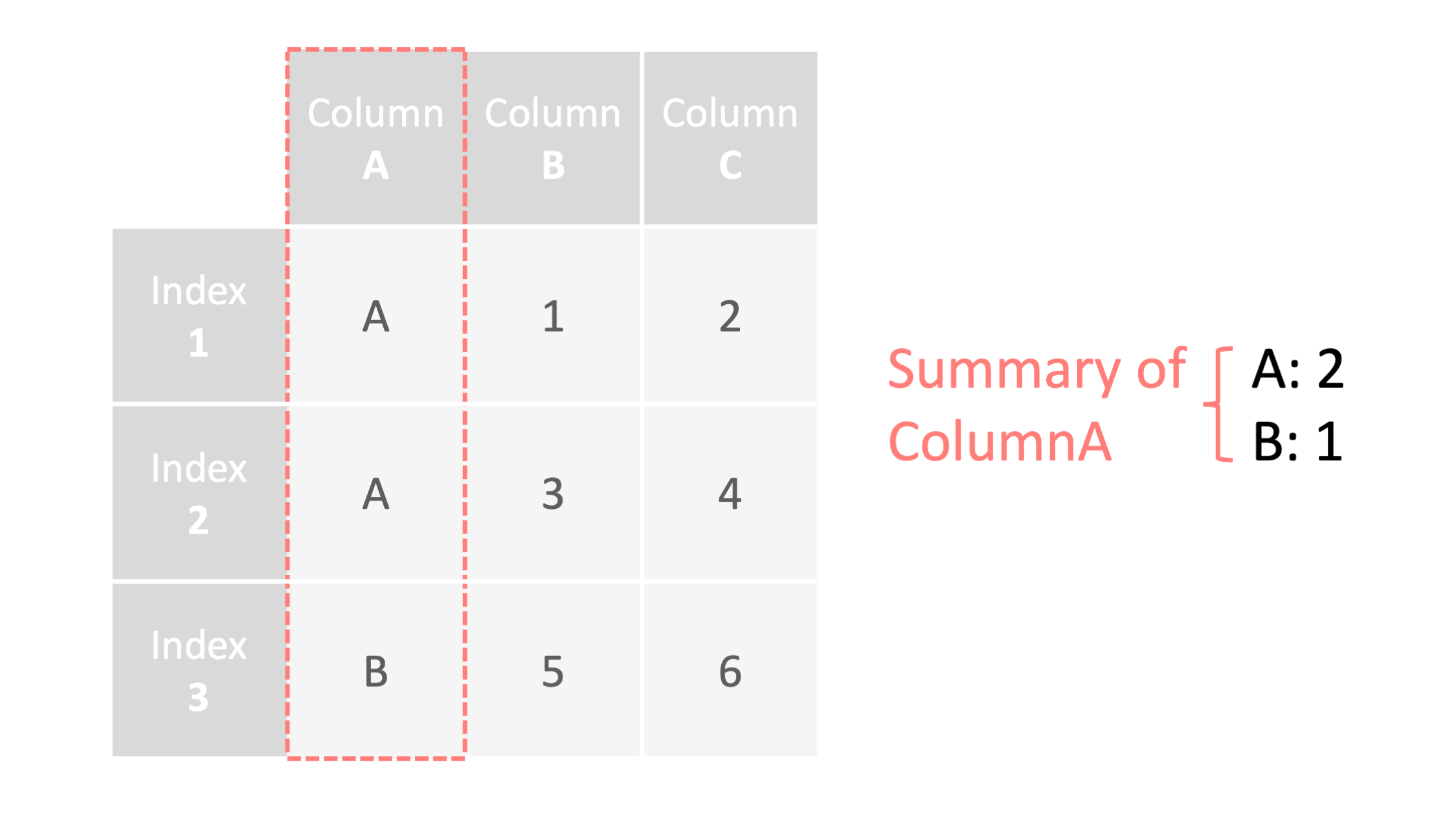
例1: データの出現数の確認 ▽
import pandas as pd
#### データの出現数の確認 ####
"""取り込むdata.csv の中身
,columnA,columnB,columnC
index1,A,1,2
index2,A,3,4
index3,B,7,8
"""
df = pd.read_csv("data.csv",index_col=0)
#columnA列の値の出現数を確認する
print("columnA:\n", df["columnA"].value_counts())
columnA=
A
2
B
1
Name: columnA, dtype: int64
DataFrameの欠損値の数を確認
command
df.isnull().sum()
df.isnull().sum()
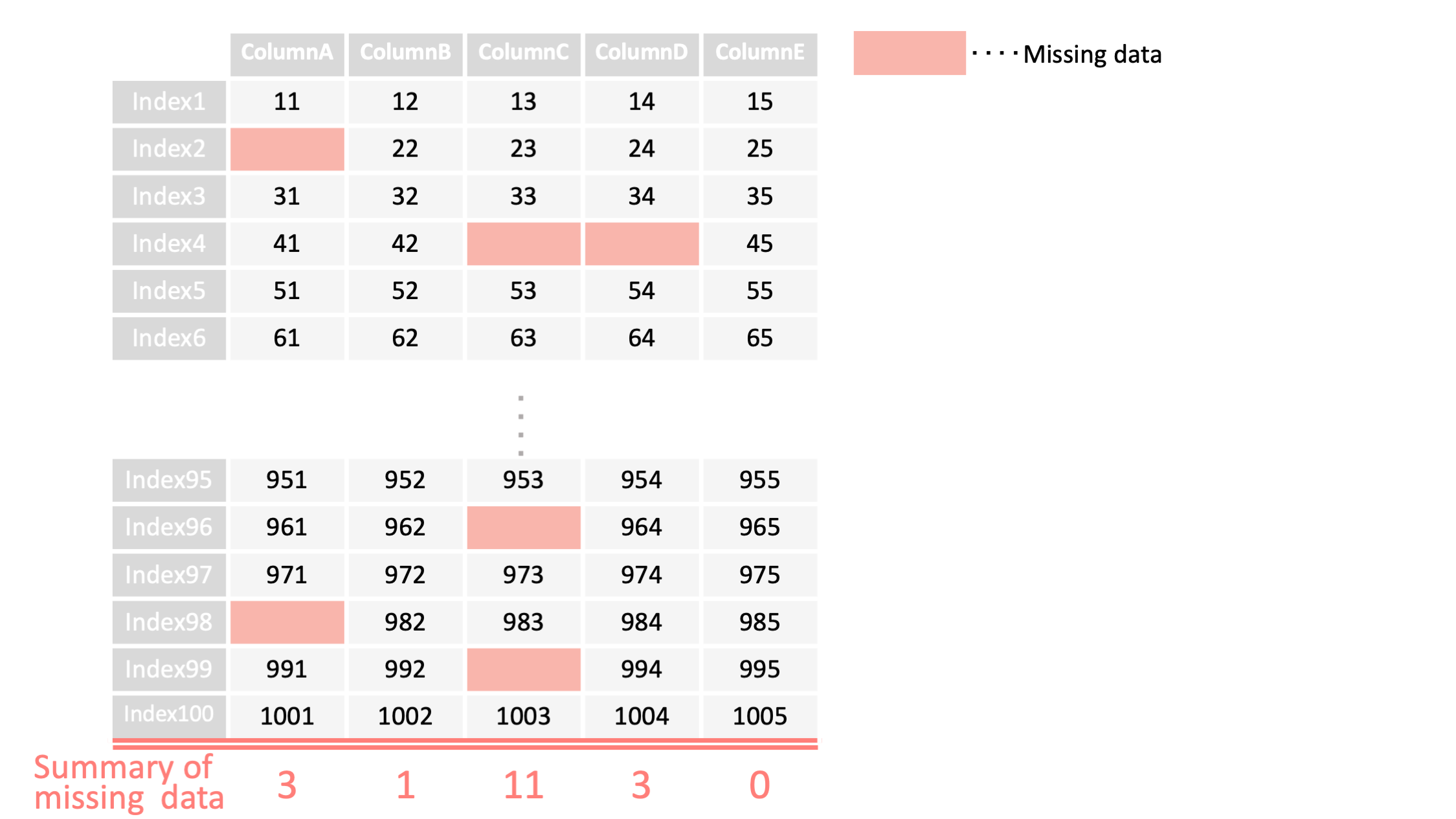
例1: 欠損値の確認 ▽
import pandas as pd
#### 各列の欠損値を参照する ####
"""取り込むdata.csvの中身
,columnA,columnB,columnC,columnD,columnE
index1,11,12,13,14,15
index2,,22,23,24,25
index3,31,32,33,34,35
index4,41,42,,,45
index5,51,52,53,54,55
... ... ... ... ... ...
index96,961,962,,964,965
index97,971,972,973,974,975
index98,,982,983,984,985
index99,991,992,,994,995
index100,1001,1002,1003,1004,1005
"""
df = pd.read_csv("data.csv", index_col=0)
#DataFrame全体の欠損値を調べる
df.isnull().sum()
#列を指定して欠損値を調べる
print('df["columnA"]=',df["columnA"].isnull().sum())
#DataFrame全体の欠損値の数
columnA
3
columnB
1
columnC
11
columnD
3
columnE
0
dtype: int64
#列を指定した欠損値の数
column["A"]= 3
DataFrameを整形
DataFrameの行列の反転
command
df.T
df.T
例1: データフレームの反転 ▽
import pandas as pd
#### データフレームを反転させる ####
"""読み込むdata.csvの中身
,columnA,columnB,columnC
index1,1,2,3
index2,4,5,6
index3,7,8,9
"""
df1 = pd.read_csv("data.csv", index_col=0)
#df1を反転させてdf2に代入する
df2 = df1.T
print("df2=", df2)
#df2の中身
df2=
index1
index2
index3
columnA
1
4
7
columnB
2
5
8
columnC
3
6
9
DataFrameの結合
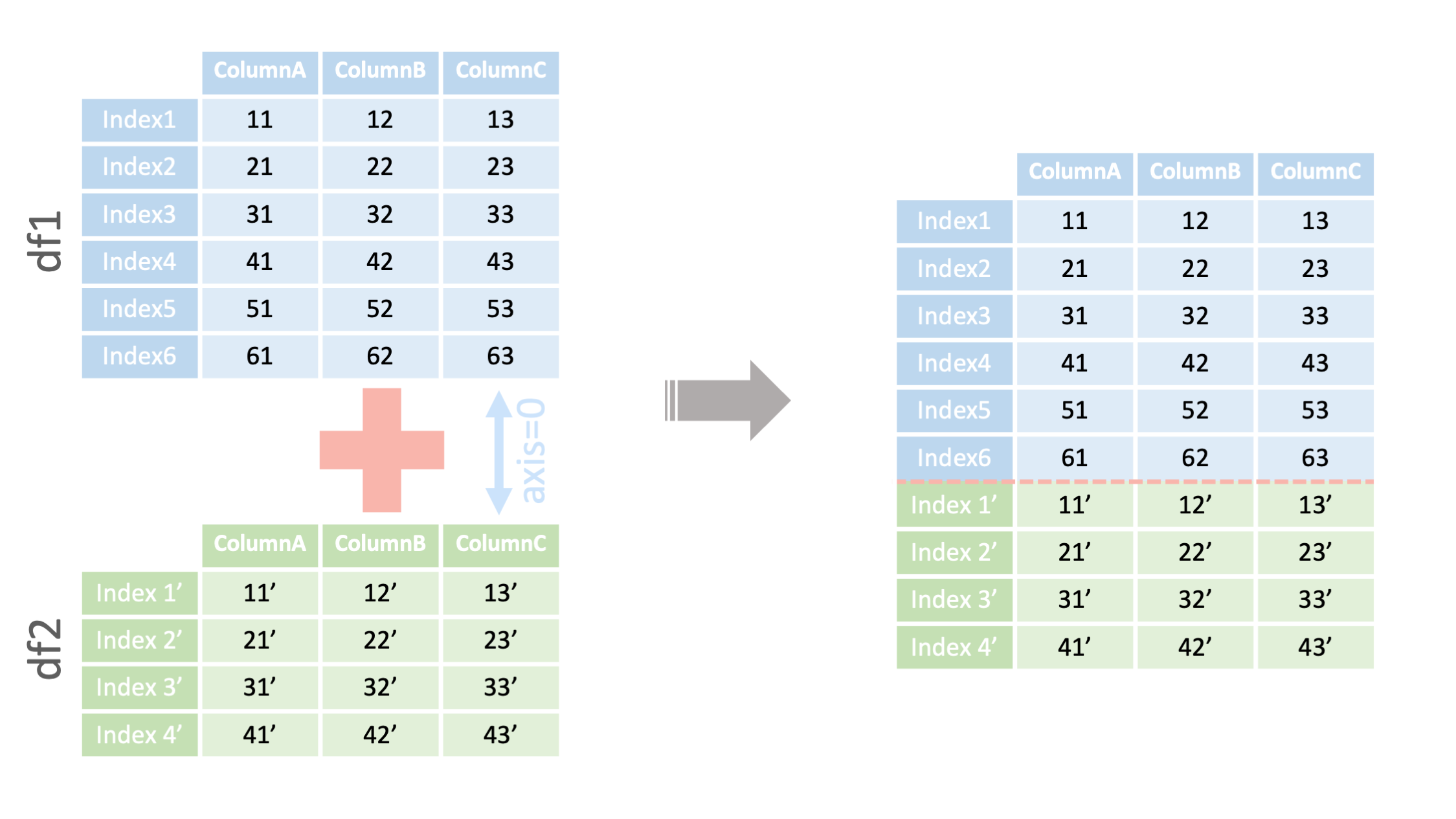
command
pd.concat([df1, df2],
axis=0)
axis=0)
<- 結合するデータフレームの指定
<- axis=0で行方向に結合
<- axis=0で行方向に結合
pd.concat([df1, df2]①, axis=0②)
① 結合するデータフレームの指定
② axis=0で行方向に結合
② axis=0で行方向に結合
*列名を一致させる必要があることに注意
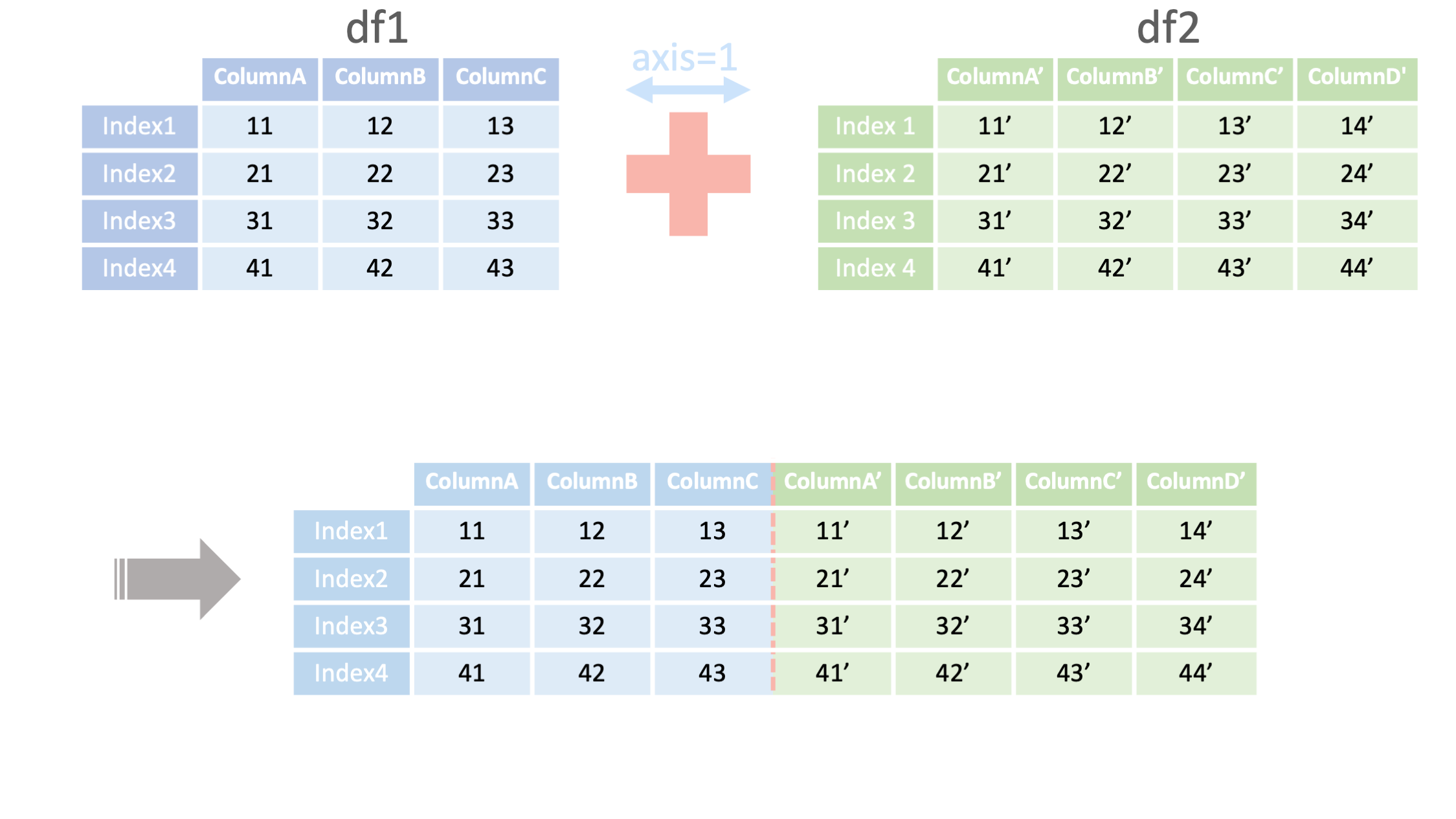
pd.concat([df1, df2],
axis=1)
axis=1)
<- 結合するデータフレームの指定
<- axis=1で列方向に結合
<- axis=1で列方向に結合
pd.concat([df1, df2]①, axis=1②)
① 結合するデータフレームの指定
② axis=1で列方向に結合
② axis=1で列方向に結合
*インデックスを一致させる必要があることに注意
例1: 行方向(axis=0)の結合 ▽
import pandas as pd
#### 2つのDataFrameを行方向に結合する ####
#結合するためのデータ1
"""取り込むdata1.csvの中身
,columnA,columnB,columnC
index1,11,12,13
index2,21,22,23
index3,31,32,33
index4,41,42,43
index5,51,52,53
index6,61,62,63
"""
df1 = read_csv("data1.csv", index_col=0)
##行方向にdf1とdf2を結合する
#結合するためのデータ2
"""取り込むdata2.csvの中身
,columnA,columnB,columnC
index1',11',12',13'
index2',21',22',23'
index3',31',32',33'
index4',41',42',43'
"""
df2 = read_csv("data2.csv", index_col=0)
pd.concat([df1, df2], axis=0)
##列名が一致していない場合
#結合するデータ3
"""取り込むdata3.csvの中身
,columnA',columnB',columnC'
index1',11',12',13'
index2',21',22',23'
index3',31',32',33'
index4',41',42',43'
"""
df3 = pd.read_csv("data3.csv", index_col=0)
pd.concat([df1, df3],axis=0)
#列名が一致するデータを結合する場合
columnA
columnB
columnC
index1
11
12
13
index2
21
22
23
index3
31
32
33
index4
41
42
43
index5
51
52
53
index6
61
62
63
index1'
11'
12'
13'
index2'
21'
22'
23'
index3'
31'
32'
33'
index4'
41'
42'
43'
#列名が一致しないデータ同士を結合する場合
columnA
columnB
columnC
columnA'
columnB'
columnC'
index1
11
12
13
NaN
NaN
NaN
index2
21
22
23
NaN
NaN
NaN
index3
31
32
33
NaN
NaN
NaN
index4
41
42
43
NaN
NaN
NaN
index1'
NaN
NaN
NaN
11'
12'
13'
index2'
NaN
NaN
NaN
21'
22'
23'
index3'
NaN
NaN
NaN
31'
32'
33'
index4'
NaN
NaN
NaN
41'
42'
43'
例2: 列方向(axis=1)の結合 ▽
import pandas as pd
#### 2つのDataFrameを列方向に結合する ####
#結合するためのデータ1
"""取り込むdata1.csvの中身
,columnA,columnB,columnC
index1,11,12,13
index2,21,22,23
index3,31,32,33
index4,41,42,43
"""
df1 = read_csv("data1.csv", index_col=0)
##列方向にdf1とdf2を結合する
#結合するためのデータ2
"""取り込むdata2.csvの中身
,columnA',columnB',columnC',columnD'
index1,11',12',13',14'
index2,21',22',23',24'
index3,31',32',33',34'
index4,41',42',43',44'
"""
df2 = read_csv("data2.csv", index_col=0)
pd.concat([df1, df2], axis=1)
##インデックスが一致しない場合
#結合するためのデータ3
"""取り込むdata3.csvの中身
,columnA',columnB',columnC'
index1',11',12',13'
index2',21',22',23'
index3',31',32',33'
index4',41',42',43'
"""
df3 = pd.read_csv("data3.csv", index_col=0)
pd.concat([df1, df3],axis=1)
#インデックスを一致させた場合
columnA
columnB
columnC
columnA'
columnB'
columnC'
columnD'
index1
11
12
13
11'
12'
13'
14'
index2
21
22
23
21'
22'
23'
24'
index3
31
32
33
31'
32'
33'
34'
index4
41
42
43
41'
42'
43'
44'
#インデックスを一致させない場合
columnA
columnB
columnC
columnA'
columnB'
columnC'
index1
11
12
13
NaN
NaN
NaN
index2
21
22
23
NaN
NaN
NaN
index3
31
32
33
NaN
NaN
NaN
index4
41
42
43
NaN
NaN
NaN
index1'
NaN
NaN
NaN
11'
12'
13'
index2'
NaN
NaN
NaN
21'
22'
23'
index3'
NaN
NaN
NaN
31'
32'
33'
index4'
NaN
NaN
NaN
41'
42'
43'
DataFrameの内部結合・外部結合
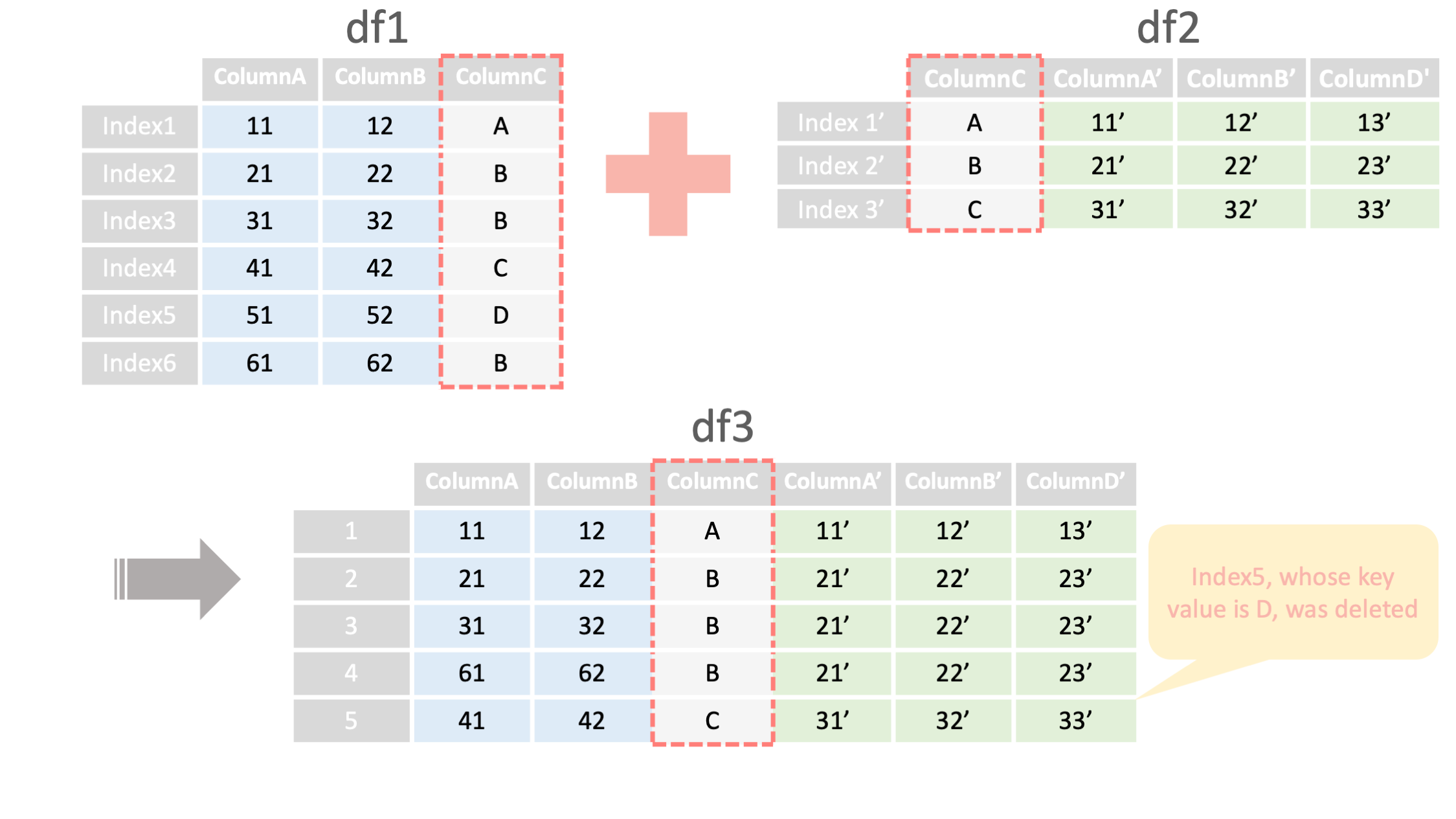
command
df3 = df1.merge(df2,
how="inner",
on="ColumnC")
how="inner",
on="ColumnC")
<- 結合するdataframeを指定
<- how="inner"で内部結合
<- 結合キーとなる列の指定
<- how="inner"で内部結合
<- 結合キーとなる列の指定
df3 = df1.merge(df2①,
how="inner"②,
on="ColumnC"③)
how="inner"②,
on="ColumnC"③)
① 結合するdataframeの指定
② how="inner"で内部結合
③ 結合キーとなる列の指定
② how="inner"で内部結合
③ 結合キーとなる列の指定
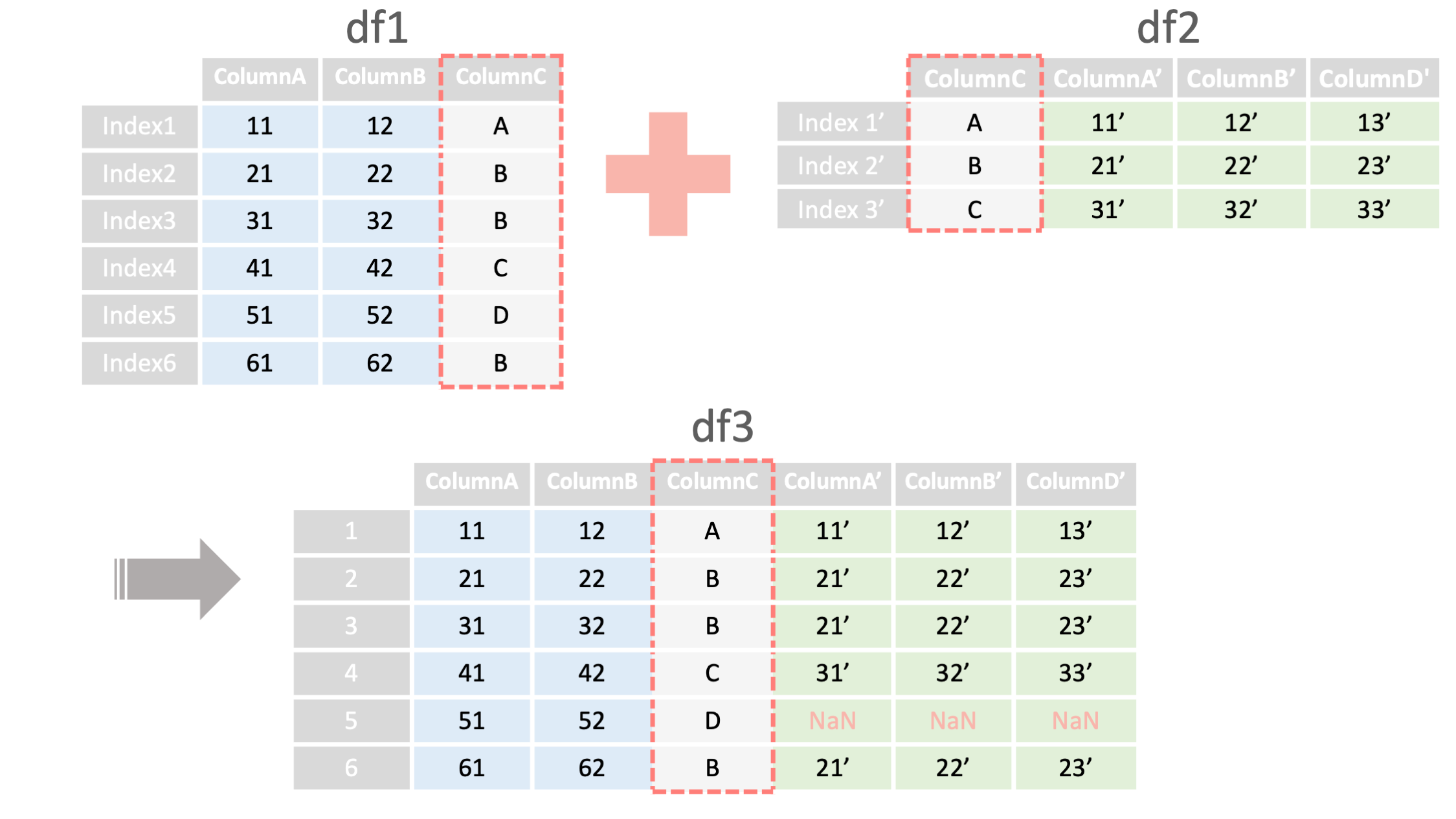
df3 = df1.merge(df2,
how="left",
on="ColumnC")
how="left",
on="ColumnC")
<- 結合するdataframeを指定
<- how="left"で外部結合*
<- 結合キーとなる列の指定
<- how="left"で外部結合*
<- 結合キーとなる列の指定
df3 = df1.merge(df2①,
how="left"②,
on="ColumnC"③)
how="left"②,
on="ColumnC"③)
① 結合するdataframeの指定
② how="inner"で外部結合*
③ 結合キーとなる列の指定
② how="inner"で外部結合*
③ 結合キーとなる列の指定
*上記例は左外部結合
例1: 内部結合 ▽
import pandas as pd
#### 2つのDataFrameを内部結合する ####
#結合するためのデータ1
"""読み込むdata.csvの中身
,columnA,columnB,columnC
index1,11,12,A
index2,21,22,B
index3,31,32,B
index4,41,42,C
index5,51,52,D
index6,61,62,B
"""
df1 = pd.read_csv("data1.csv", index_col=0)
#結合するためのデータ2
df2 = read_csv("data2.csv", index_col=0)
"""準備したdf2は以下
,columnC,columnA',columnB',columnD'
index1,A,11',12',13'
index2,B,21',22',23'
index3,C,31',32',33'
"""
df2 = pd.read_csv("data2.csv", index_col=0)
#列"columnC"で内部結合する
df3 = df1.merge(df2, how="inner",on="columnC")
print("df3=", df3)
#内部結合の結果 *df1 columnC列の値"D"であった[index5,51,52,D]が削除されている
#結合後は、結合元のdf1、df2のindexが削除される
#結合後は、結合キーでソートされる(sort=Falseを指定しても効果が確認できなかった)
df3=
columnA
columnB
columnC
columnA'
columnB'
columnD'
0
11
12
A
11'
12'
13'
1
21
22
B
21'
22'
23'
2
31
32
B
21'
22'
23'
3
41
42
B
21'
22'
23'
4
61
62
C
31'
32'
33'
例2: 外部結合 ▽
import pandas as pd
#結合するためのデータ1
df1 = read_csv("data1.csv", index_col=0)
"""準備したdf1は以下
,columnA,columnB,columnC
index1,11,12,A
index2,21,22,B
index3,31,32,B
index4,41,42,C
index5,51,52,D
index6,61,62,B
"""
#結合するためのデータ2
df2 = read_csv("data2.csv", index_col=0)
"""準備したdf2は以下
,columnC,columnA',columnB',columnD'
index1,A,11',12',13'
index2,B,21',22',23'
index3,C,31',32',33'
"""
#列"columnC"で外部結合する
df3 = df1.merge(df2, how="left",on="columnC")
print("df3=", df3)
#外部結合の結果 *df2にて、columnC列の値"D"が無いため、[4 51 52 D NaN NaN NaN]となっている
#結合後は、結合元のdf1、df2のindexが削除される
df3=
columnA
columnB
columnC
columnA'
columnB'
columnD'
0
11
12
A
11'
12'
13'
1
21
22
B
21'
22'
23'
2
31
32
B
21'
22'
23'
3
41
42
C
31'
32'
33'
4
51
52
D
NaN
NaN
NaN
5
61
62
B
21'
22'
23'
特定の行と列の取り出し
command
df2 = df1.loc[1:3,
"B":"D"]
"B":"D"]
<- 行データの取り出す範囲を指定
<- 列データの取り出す範囲を指定
<- 列データの取り出す範囲を指定
df2 = df1.loc[1:3①, "B":"D"②]
① 行データの取り出す範囲を指定
② 列データの取り出す範囲を指定
② 列データの取り出す範囲を指定
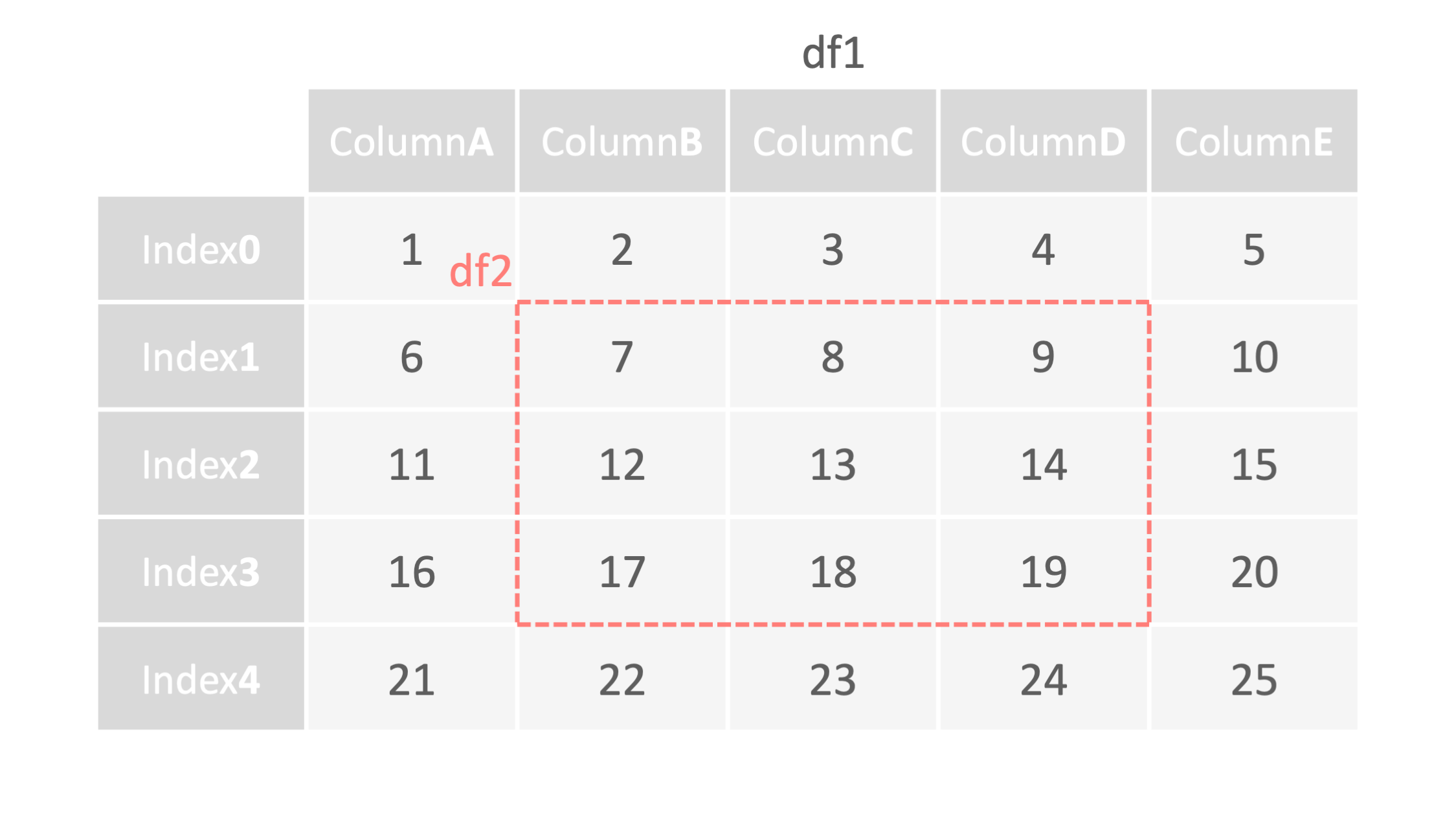
例1: インデックス名がない場合 ▽
import pandas as pd
#### 特定の行・列を取り出す ####
"""読み込むdata.csvの中身
,columnA,columnB,columnC,columnD,columnE
1,2,3,4,5
6,7,8,9,10
11,12,13,14,15
16,17,18,19,20
21,22,23,24,25
"""
df1 = pd.read_csv("data.csv")
#df1(元のデータフレームの中身)確認
print("df1=", df1)
#特定の行・列を取り出す
df2 = df1.loc[1:3, "columnB":"columnD"]
print("df2=", df2)
#df1の中身
df1=
columnA
columnB
columnC
columnD
columnE
0
1
2
3
4
5
1
6
7
8
9
10
2
11
12
13
14
15
3
16
17
18
19
20
4
21
22
23
24
25
#df2の中身
df2=
columnB
columnC
columnD
1
7
8
9
2
12
13
14
3
17
18
19
例2: インデックス名がある場合 ▽
import pandas as pd
#特定の行・列を取り出される元データ
"""読み込むdata.csvの中身
,columnA,columnB,columnC,columnD,columnE
index1,1,2,3,4,5
index2,6,7,8,9,10
index3,11,12,13,14,15
index4,16,17,18,19,20
index5,21,22,23,24,25
"""
df1 = pd.read_csv("data.csv")
#df1(元のデータフレームの中身)確認
print("df1=", df1)
#特定の行・列を取り出す
df2 = df1.loc["index2":"index4", "columnB":"columnD"]
print("df2=", df2)
#df1の中身
df1=
columnA
columnB
columnC
columnD
columnE
index1
1
2
3
4
5
index2
6
7
8
9
10
index3
11
12
13
14
15
index4
16
17
18
19
20
index5
21
22
23
24
25
#df2の中身
df2=
columnB
columnC
columnD
index2
7
8
9
index3
12
13
14
index4
17
18
19
DataFrameのデータを変更
DataFrameの列名・インデックス名の変更
command
df.columns = ["columnα","columnβ","columnγ"]
df.index = ["Jan", "Feb", "Mar"]
df.index = ["Jan", "Feb", "Mar"]
df.columns = ["columnα","columnβ","columnγ"]
df.index = ["Jan", "Feb", "Mar"]
df.index = ["Jan", "Feb", "Mar"]
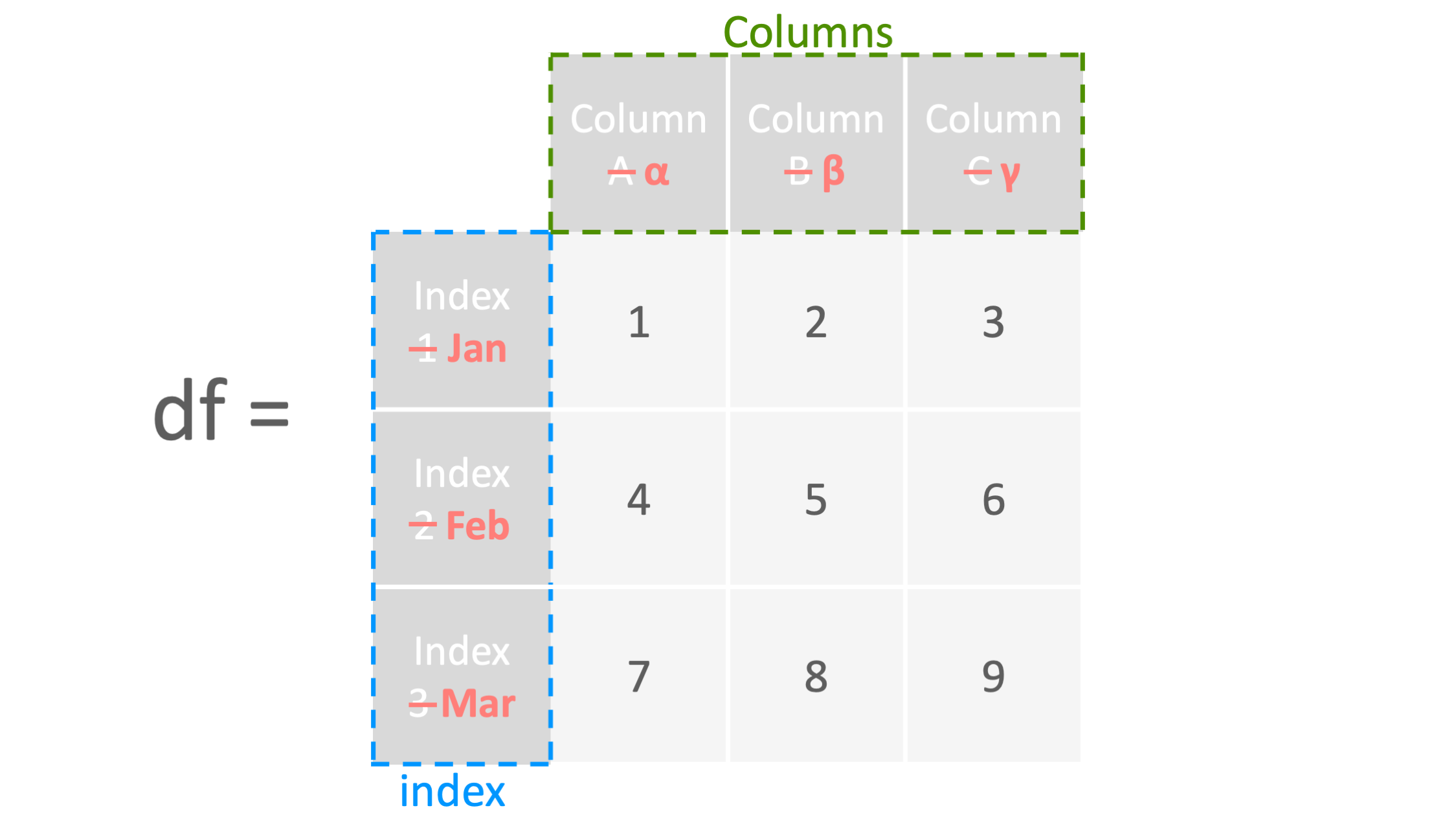
例1: 列名の変更 ▽
import pandas as pd
#### データフレームの列名を変更する ####
"""読み込むdata.csvの中身
,columnA,columnB,columnC
index1,1,2,3
index2,4,5,6
index3,7,8,9
"""
df = pd.read_csv("data.csv")
#列名を変更する(columnA->columnα,columnB->columnβ,columnC->columnγ)
df.columns = ["columnα","columnβ","columnγ"]
#列名を変更したdf
columnα
columnβ
columnγ
index1
1
2
3
index2
4
5
6
index3
7
8
9
例2: インデックスの変更 ▽
import pandas as pd
#### データフレームのインデックスを変更する ####
"""読み込むdata.csvの中身
,columnA,columnB,columnC
index1,1,2,3
index2,4,5,6
index3,7,8,9
"""
df = pd.read_csv("data.csv")
####インデックスを変更する(index1->Jan,index2->Feb,index3->Mar)
df.index = ["Jan", "Feb", "Mar"]
#インデックスを変更したdf
columnA
columnB
columnC
Jan
1
2
3
Feb
4
5
6
Mar
7
8
9
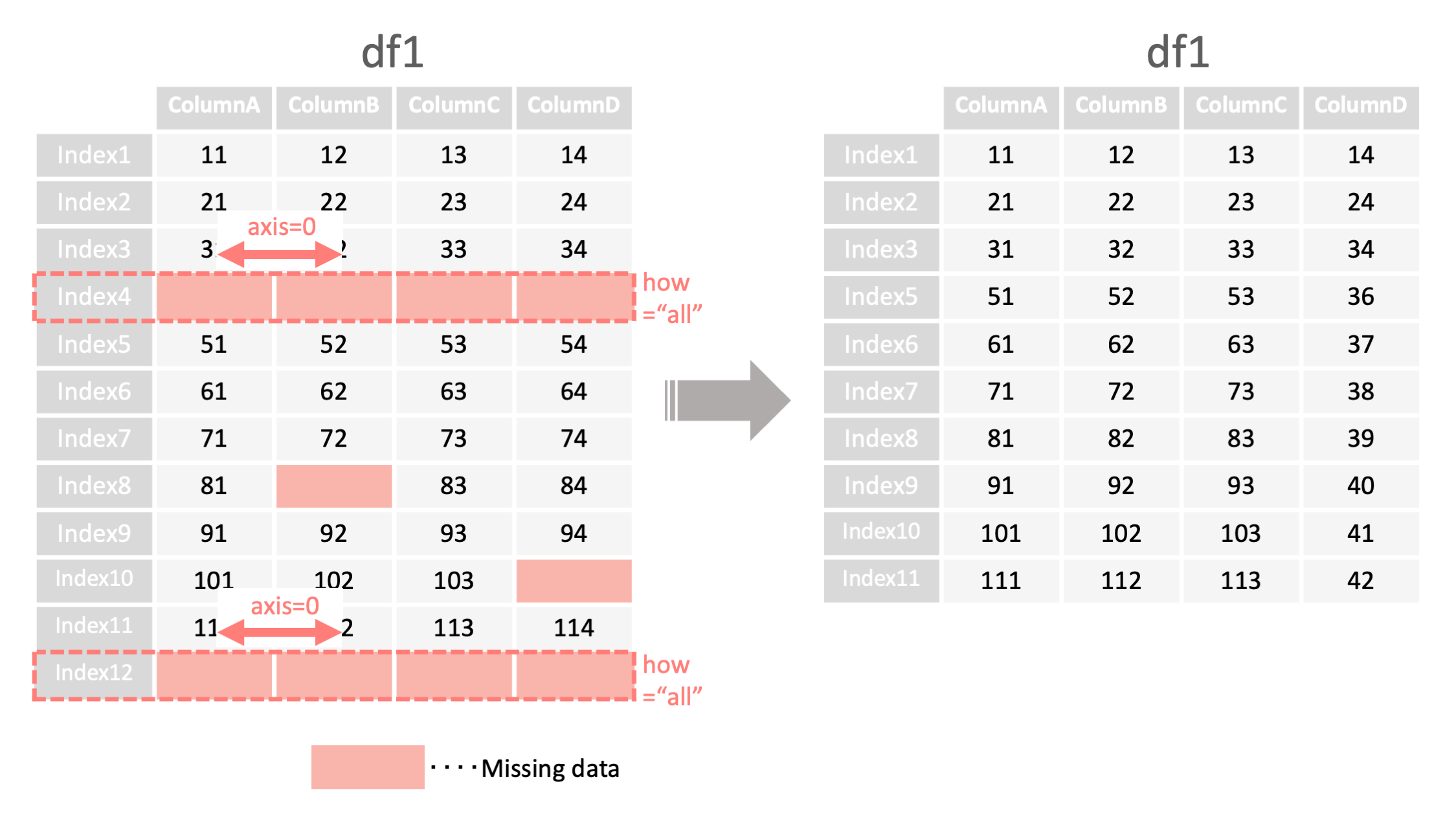
DataFrameの欠損値を含む行・列の削除
command
df1.dropna(how="all",
axis=0,
inplace=True)
axis=0,
inplace=True)
<- any:1つでも欠損値があれば all:全てが欠損値の場合
<- 0:欠損値がある行を削除 1:欠損値がある列を削除
<- True:df自体を変更 False:df自体は変更しない*
<- 0:欠損値がある行を削除 1:欠損値がある列を削除
<- True:df自体を変更 False:df自体は変更しない*
df1.dropna(how="all"①,
axis=0②,
inplace=True③)
axis=0②,
inplace=True③)
① 結合するデータフレームの指定
② axis=0で行方向に結合
③ True:df自体を変更 False:df自体は変更しない*
② axis=0で行方向に結合
③ True:df自体を変更 False:df自体は変更しない*
*Falseの場合、別のdfに代入する場合に利用する(ex. df'=df.dropna(… =False))
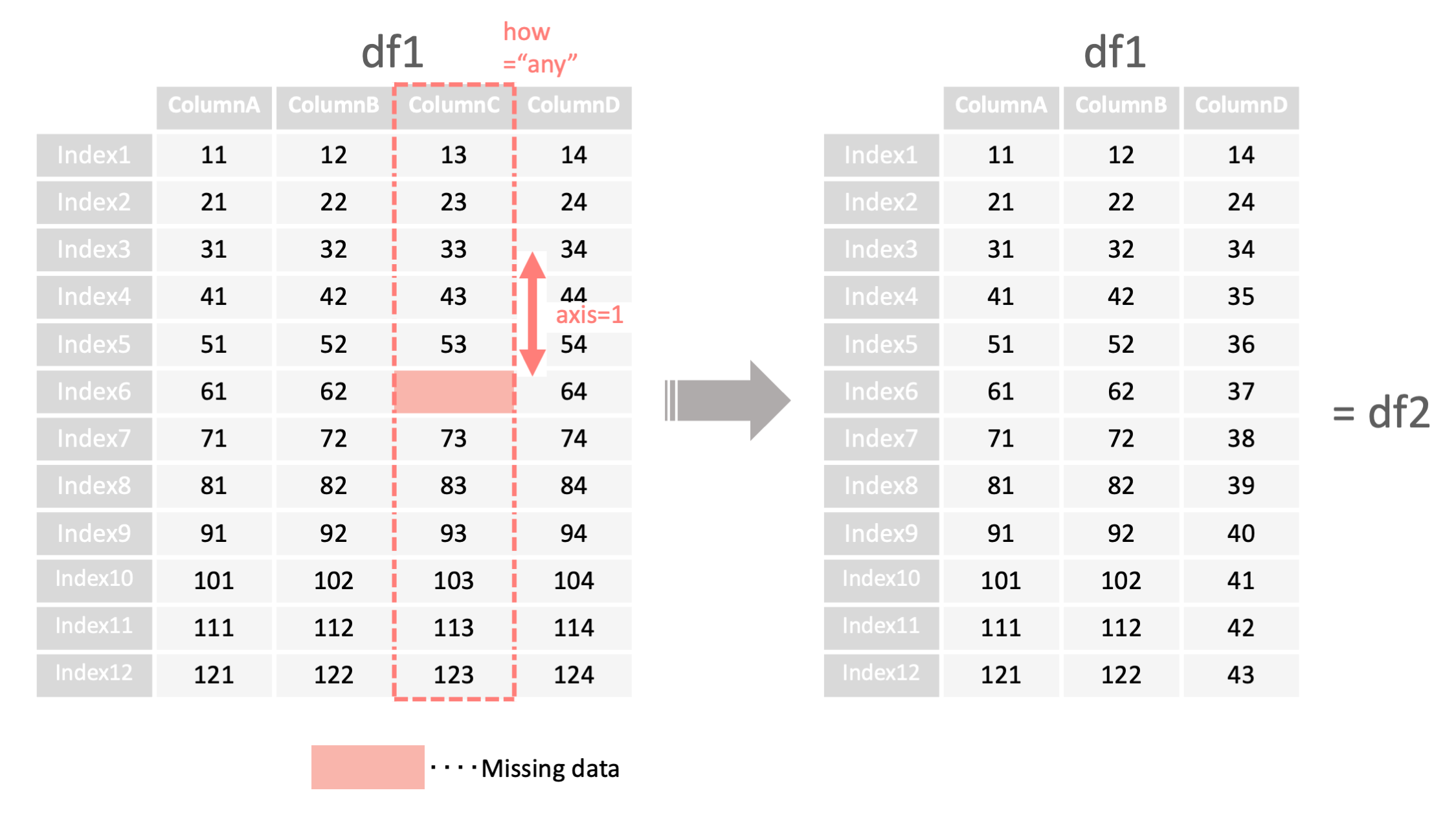
df2 = df1.dropna(how="any",
axis=1,
inplace=False)
axis=1,
inplace=False)
<- any:1つでも欠損値があれば all:全てが欠損値の場合
<- 0:欠損値がある行を削除 1:欠損値がある列を削除
<- True:df自体を変更 False:df自体は変更しない*
<- 0:欠損値がある行を削除 1:欠損値がある列を削除
<- True:df自体を変更 False:df自体は変更しない*
df2 = df1.dropna(how="any"①,
axis=1②,
inplace=True③)
axis=1②,
inplace=True③)
① 結合するデータフレームの指定
② axis=0で行方向に結合
③ True:df自体を変更 False:df自体は変更しない*
② axis=0で行方向に結合
③ True:df自体を変更 False:df自体は変更しない*
*Falseの場合、別のdfに代入する場合に利用する(ex. df'=df.dropna(… =False))
例1: すべての値が欠損値である行を削除 ▽
import pandas as pd
#### 値すべてが欠損値である行を削除する ####
"""読み込むdata.csvの中身
,columnA,columnB,columnC,columnD
index1,11,12,13,14
index2,21,22,23,24
index3,31,32,33,34
index4,,,,
index5,51,52,53,54
index6,61,62,63,64
index7,71,72,73,74
index8,81,,83,84
index9,91,92,93,94
index10,101,102,103,
index11,111,112,113,114
index12,,,,
"""
df1 = read_csv("data.csv", index_col=0)
####すべての値が欠損値である行をdfから削除する
df1.dropna(how="all",axis=0,inplace=True)
print("df1=", df1)
#欠損値を削除したdf1
df1=
columnA
columnB
columnC
columnD
index1
11
12
13
14
index2
21
22
23
24
index3
31
32
33
34
index5
51
52
53
54
index6
61
62
63
64
index7
71
72
73
74
index8
81
NaN
83
84
index9
91
92
93
94
index10
101
102
103
104
index11
111
112
113
114
例2: 欠損値を含む列を削除 ▽
import pandas as pd
#### 欠損値を1つでも含む列をdfから削除する ####
"""読み込むdata.csvの中身
columnA,columnB,columnC,columnD
index1,11,12,13,14
index2,21,22,23,24
index3,31,32,33,34
index4,41,42,43,44
index5,51,52,53,54
index6,61,62,,64
index7,71,72,73,74
index8,81,82,83,84
index9,91,92,93,94
index10,101,102,103,104
index11,111,112,113,114
index12,121,122,123,124
"""
df1 = read_csv("data.csv", index_col=0)
df2 = df1.dropna(how="any",axis=1,inplace=False)
print("df2=", df2)
#欠損値を削除したdf2
df2=
columnA
columnB
columnD
index1
11
12
14
index2
21
22
24
index3
31
32
34
index4
41
42
44
index5
51
52
54
index6
61
62
64
index7
71
72
74
index8
81
82
84
index9
91
92
94
index10
101
102
104
index11
111
112
114
index12
121
122
124
DataFrameの欠損値を穴埋め
command
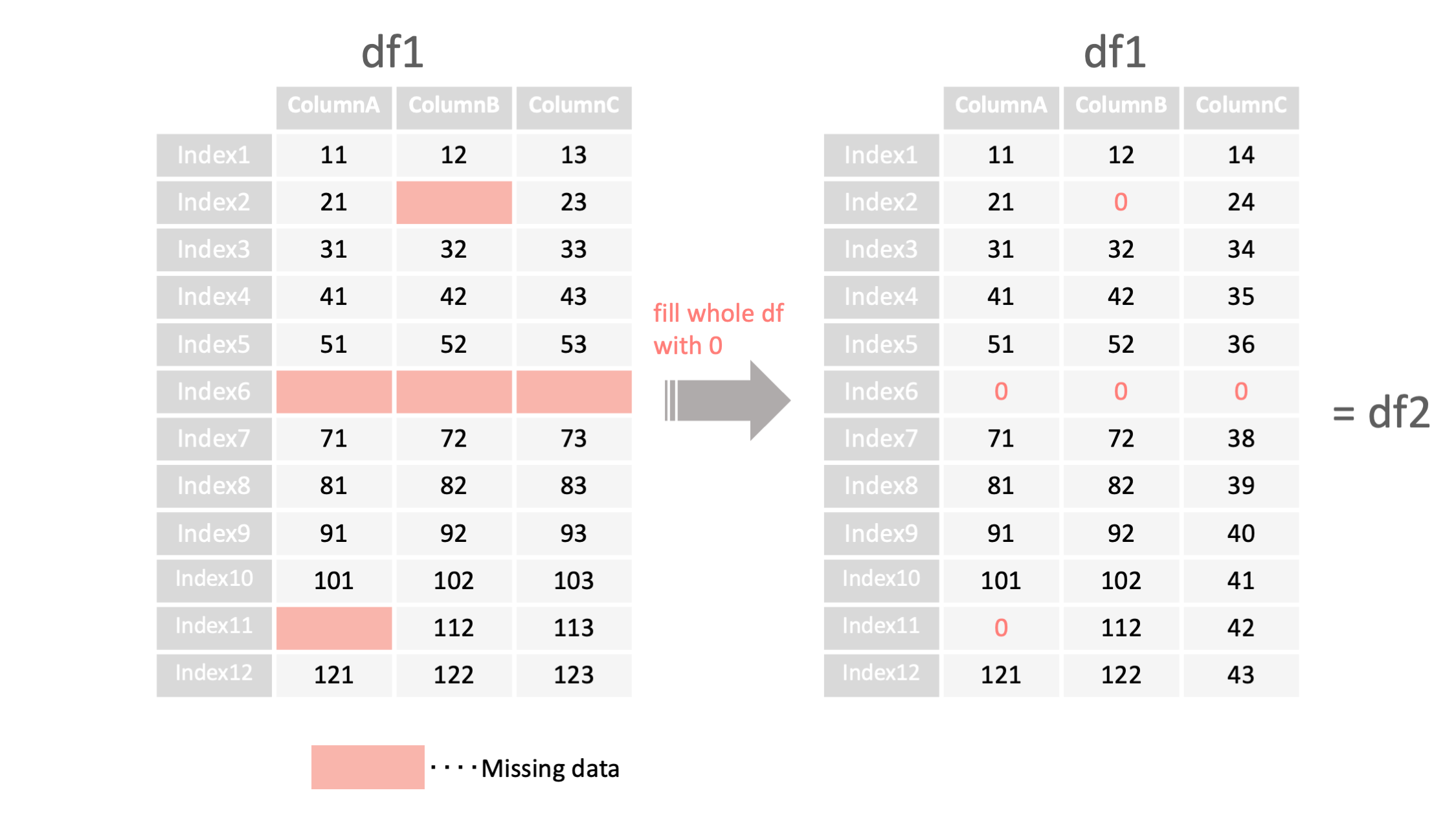
df2 = df1.fillna(0)
<- 括弧内の値で欠損値を埋める
df2 = df1.fillna(0①)
① 括弧内の値で欠損値を埋める
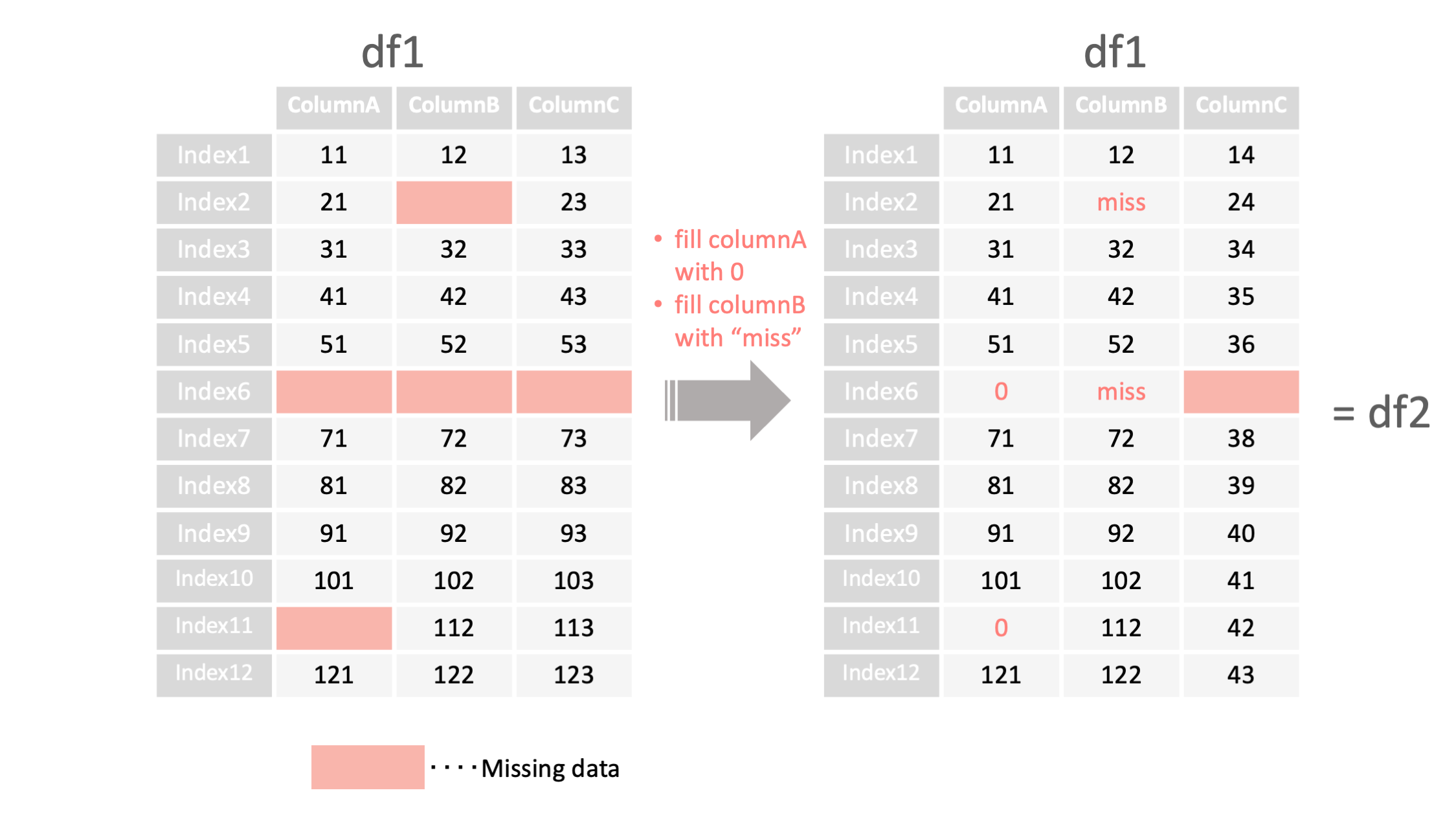
df2 = df1.fillna({"columnA":0, "columnB":"miss"},
inplace=False)
inplace=False)
<- 列名と埋める値を設定する
<- True:df自体を変更 False:df自体は変更しない*
<- True:df自体を変更 False:df自体は変更しない*
df2 = df1.fillna({"columnA":0, "columnB":"miss"}①,
inplace=False②)
inplace=False②)
① 列名と埋める値を設定する
② True:df自体を変更 False:df自体は変更しない*
② True:df自体を変更 False:df自体は変更しない*
*Falseの場合、別のdfに代入する場合に利用する(ex. df'=df.fillna(… =False))
例1: df内の欠損値を一括穴埋め ▽
import pandas as pd
####欠損値を削除するためのデータ
"""読み込むdata.csvの中身
columnA,columnB,columnC
index1,11,12,13
index2,21,,23
index3,31,32,33
index4,41,42,43
index5,51,52,53
index6,,,,
index7,71,72,73
index8,81,82,83
index9,91,92,93
index10,101,102,103
index11,,112,113
index12,121,122,123
"""
df1 = read_csv("data.csv", index_col=0)
#すべての欠損値を0で埋める
df2 = df1.fillna(0)
print("df2=", df2)
#df2の中身
df2=
columnA
columnB
columnC
index1
11
12
13
index2
21
0
23
index3
31
32
33
index4
41
42
43
index5
51
52
53
index6
0
0
0
index7
71
72
73
index8
81
82
83
index9
91
92
93
index10
101
102
103
index11
0
112
113
index12
121
122
123
例2: 列毎に欠損値を穴埋め ▽
import pandas as pd
#### 欠損値を削除するためのデータ ####
"""準備読み込むdata.csvの中身
,columnA,columnB,columnC
index1,11,12,13
index2,21,,23
index3,31,32,33
index4,41,42,43
index5,51,52,53
index6,,,,
index7,71,72,73
index8,81,82,83
index9,91,92,93
index10,101,102,103
index11,,112,113
index12,121,122,123
"""
df1 = read_csv("data.csv", index_col=0)
#A列の欠損値を0、B列の欠損値を文字列"miss"で埋める(C列の欠損値はそのまま)
df2 = df1.fillna({"columnA":0, "columnB":"miss"},inplace=False)
print("df2=", df2)
#df2の中身
df2=
columnA
columnB
columnC
index1
11
12
13
index2
21
miss
23
index3
31
32
33
index4
41
42
43
index5
51
52
53
index6
0
miss
NaN
index7
71
72
73
index8
81
82
83
index9
91
92
93
index10
101
102
103
index11
0
112
113
index12
121
122
123
DataFrameを計算
DataFrameの各列の代表値を計算
command
df.mean()
df.var()
df.std()
df.median()
df.sum()
df.max()
df.min()
df.mode()
df.var()
df.std()
df.median()
df.sum()
df.max()
df.min()
df.mode()
<- 列ごとの平均値
<- 列ごとの分散
<- 列ごとの標準偏差
<- 列ごとの中央値
<- 列ごとの合計値
<- 列ごとの最大値
<- 列ごとの最小値
<- 列ごとの最頻値
<- 列ごとの分散
<- 列ごとの標準偏差
<- 列ごとの中央値
<- 列ごとの合計値
<- 列ごとの最大値
<- 列ごとの最小値
<- 列ごとの最頻値
df.mean()①
df.var()②
df.std()③
df.median()④
df.sum()⑤
df.max()⑥
df.min()⑦
df.mode()⑧
df.var()②
df.std()③
df.median()④
df.sum()⑤
df.max()⑥
df.min()⑦
df.mode()⑧
①列ごとの平均値
②列ごとの分散
③列ごとの標準偏差
④列ごとの中央値
⑤列ごとの合計値
⑥列ごとの最大値
⑦列ごとの最小値
⑧列ごとの最頻値
②列ごとの分散
③列ごとの標準偏差
④列ごとの中央値
⑤列ごとの合計値
⑥列ごとの最大値
⑦列ごとの最小値
⑧列ごとの最頻値
例1: 平均値の確認 ▽
import pandas as pd
#### 平均値を調べる ####
"""読み込むdata.csvの中身
,columnA,columnB,columnC,columnD,columnE,columnF
index1,1,2,3,5,8,3
index2,4,8,2,0,2,2
index3,2,2,4,6,0,6
index4,5,5,0,5,5,0
index5,3,3,7,5,8,2
index6,7,5,1,5,8,1
index7,2,2,6,5,2,7
"""
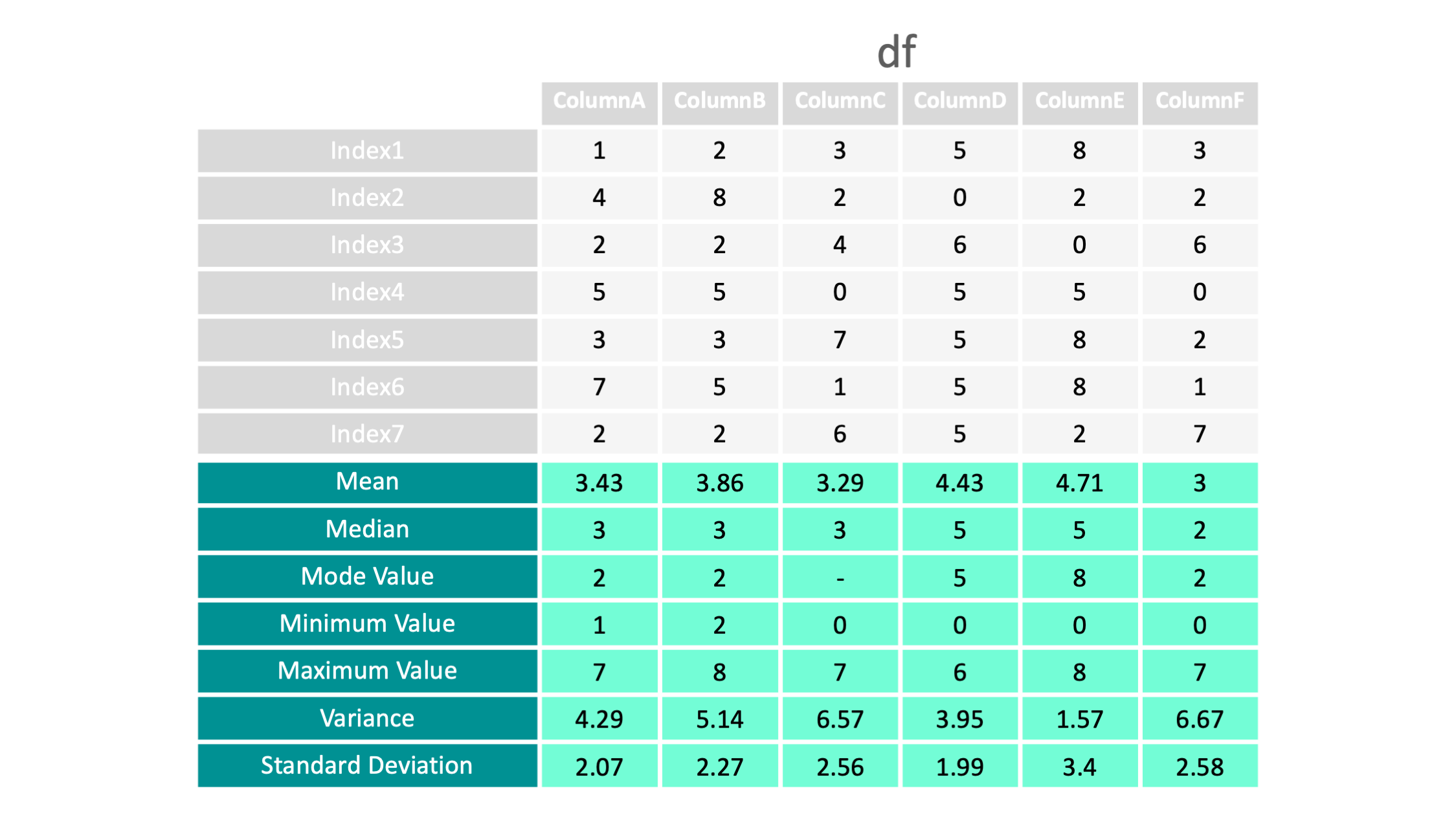
df = read_csv("data.csv", index_col=0)
df.mean()
#dfの平均値
columnA
3.428571
columnB
3.857143
columnC
3.285714
columnD
4.428571
columnE
4.714286
columnF
3.000000
例2: 分散の確認 ▽
import pandas as pd
#### 分散を調べる ####
"""読み込むdata.csvの中身
columnA,columnB,columnC,columnD,columnE,columnF
index1,1,2,3,5,8,3
index2,4,8,2,0,2,2
index3,2,2,4,6,0,6
index4,5,5,0,5,5,0
index5,3,3,7,5,8,2
index6,7,5,1,5,8,1
index7,2,2,6,5,2,7
"""
df = read_csv("data.csv", index_col=0)
df.var()
#dfの分散
columnA
4.285714
columnB
5.142857
columnC
6.571429
columnD
3.952381
columnE
11.571429
columnF
6.666667
例3: 標準偏差の確認 ▽
import pandas as pd
#### 標準偏差を調べる ####
"""読み込むdata.csvの中身
,columnA,columnB,columnC,columnD,columnE,columnF
index1,1,2,3,5,8,3
index2,4,8,2,0,2,2
index3,2,2,4,6,0,6
index4,5,5,0,5,5,0
index5,3,3,7,5,8,2
index6,7,5,1,5,8,1
index7,2,2,6,5,2,7
"""
df = read_csv("data.csv", index_col=0)
df.std()
#dfの標準偏差
columnA
2.070197
columnB
2.267787
columnC
2.563480
columnD
1.988060
columnE
3.401680
columnF
2.581989
例4: 中央値の確認 ▽
import pandas as pd
#### 中央値を調べる ####
"""読み込むdata.csvの中身
,columnA,columnB,columnC,columnD,columnE,columnF
index1,1,2,3,5,8,3
index2,4,8,2,0,2,2
index3,2,2,4,6,0,6
index4,5,5,0,5,5,0
index5,3,3,7,5,8,2
index6,7,5,1,5,8,1
index7,2,2,6,5,2,7
"""
df = read_csv("data.csv", index_col=0)
df.median()
#dfの中央値
columnA
3.0
columnB
3.0
columnC
3.0
columnD
5.0
columnE
5.0
columnF
2.0
例4: 合計の確認 ▽
import pandas as pd
#### 合計値を調べる ####
"""読み込むdata.csvの中身
,columnA,columnB,columnC,columnD,columnE,columnF
index1,1,2,3,5,8,3
index2,4,8,2,0,2,2
index3,2,2,4,6,0,6
index4,5,5,0,5,5,0
index5,3,3,7,5,8,2
index6,7,5,1,5,8,1
index7,2,2,6,5,2,7
"""
df = read_csv("data.csv", index_col=0)
df.sum()
#dfの合計
columnA
24
columnB
27
columnC
23
columnD
31
columnE
33
columnF
21
columnA 24
columnB 27
columnC 23
columnD 31
columnE 33
columnF 21
例5: 最大値の確認 ▽
import pandas as pd
#### 最大値を調べる ####
"""読み込むdata.csvの中身
,columnA,columnB,columnC,columnD,columnE,columnF
index1,1,2,3,5,8,3
index2,4,8,2,0,2,2
index3,2,2,4,6,0,6
index4,5,5,0,5,5,0
index5,3,3,7,5,8,2
index6,7,5,1,5,8,1
index7,2,2,6,5,2,7
"""
df = read_csv("data.csv", index_col=0)
df.max()
#dfの最大値
columnA
7
columnB
8
columnC
7
columnD
6
columnE
8
columnF
7
例6: 最小値の確認 ▽
import pandas as pd
#### 最小値を調べる ####
"""読み込むdata.csvの中身
,columnA,columnB,columnC,columnD,columnE,columnF
index1,1,2,3,5,8,3
index2,4,8,2,0,2,2
index3,2,2,4,6,0,6
index4,5,5,0,5,5,0
index5,3,3,7,5,8,2
index6,7,5,1,5,8,1
index7,2,2,6,5,2,7
"""
df = read_csv("data.csv", index_col=0)
df.min()
#dfの最小値
columnA
1
columnB
2
columnC
0
columnD
0
columnE
0
columnF
0
例7: 最頻値の確認 ▽
import pandas as pd
#### 最頻値を調べる ####
"""読み込むdata.csvの中身
,columnA,columnB,columnC,columnD,columnE,columnF
index1,1,2,3,5,8,3
index2,4,8,2,0,2,2
index3,2,2,4,6,0,6
index4,5,5,0,5,5,0
index5,3,3,7,5,8,2
index6,7,5,1,5,8,1
index7,2,2,6,5,2,7
"""
df = read_csv("data.csv", index_col=0)
df.mode()
#dfの最頻値
columnA
columnB
columnC
columnD
columnE
columnF
0
2.0
2.0
0
5.0
8.0
2.0
1
NaN
NaN
1
NaN
NaN
NaN
2
NaN
NaN
2
NaN
NaN
NaN
3
NaN
NaN
3
NaN
NaN
NaN
4
NaN
NaN
4
NaN
NaN
NaN
5
NaN
NaN
5
NaN
NaN
NaN
6
NaN
NaN
6
NaN
NaN
NaN
7
NaN
NaN
7
NaN
NaN
NaN
コメント・お問合せ
以下のツイートの『返信』にてお願いいたします