



【E資格プロダクト開発演習】LSTMとCNNの文章分類性能比較
⚠本記事は、初学者(特にE資格講座受講者)向けであり、プロダクト開発演習の事例としての閲覧を目的に公開しています。
以下をご確認の上、記事およびコードを閲覧していただけると幸いです。
- 本記事では、2つのモデル(LSTM・CNN)の文章分類性能を比較しておりますが、ハイパーパラメータチューニングやdropoutなどの正則化は行っておらず、本質的には両モデルの優劣を正しく判断できておりません(講座理解度を示すことが演習目的であると想定して作成したため)
- 初学者や文章分類のアルゴリズムを理解したい方は、本プロダクトを作成するに当たって参考とした記事がとても分かりやすいので、そちらの閲読をおすすめいたします[1~4](特にCNNは、コードをほぼ真似させていただきました)
- 実際に提出したファイルは、『CODE』ページとなり、課題としてパスしましたが、考察に対しての正誤のフィードバックは講師側から無かったため、的外れな考察である可能性があります
- 本記事の内容やコードをE資格プロダクト開発演習へ再利用することにより、不都合・不利益が生じた場合、当方では責任は負いかねます
目次
1. プロダクト開発演習のルール
まず、受講したE資格講座のプロダクト開発演習のルールが以下となります(2021年12月時点)。
- ipynbなどに学習結果・予測デモが出力されている
- 理解した上で独自の工夫がされている痕跡(コメント)がある
- 結果について考察がされている
- 深層学習(中間層3層以上)を利用すること
参考としたCNNの文章分類モデルでは、項目4の中間層を重ねることが性能向上に寄与しないため、LSTMにて中間層を重ねることで本演習をパスしました。
2. LSTMのデータセットの準備
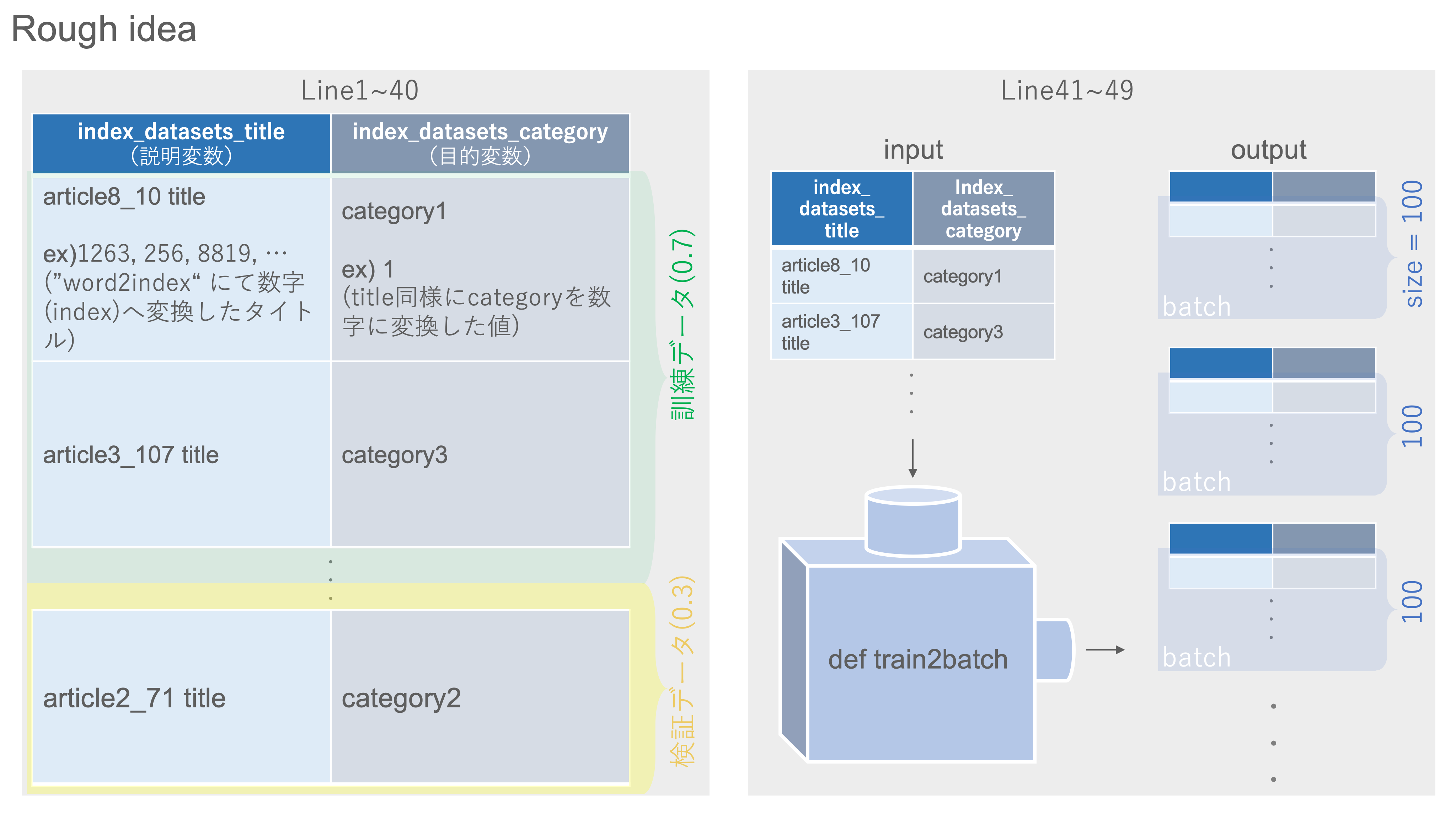
LSTM(モデル)が学習し、その性能を検証するためのデータ(説明変数と目的変数)を準備します。
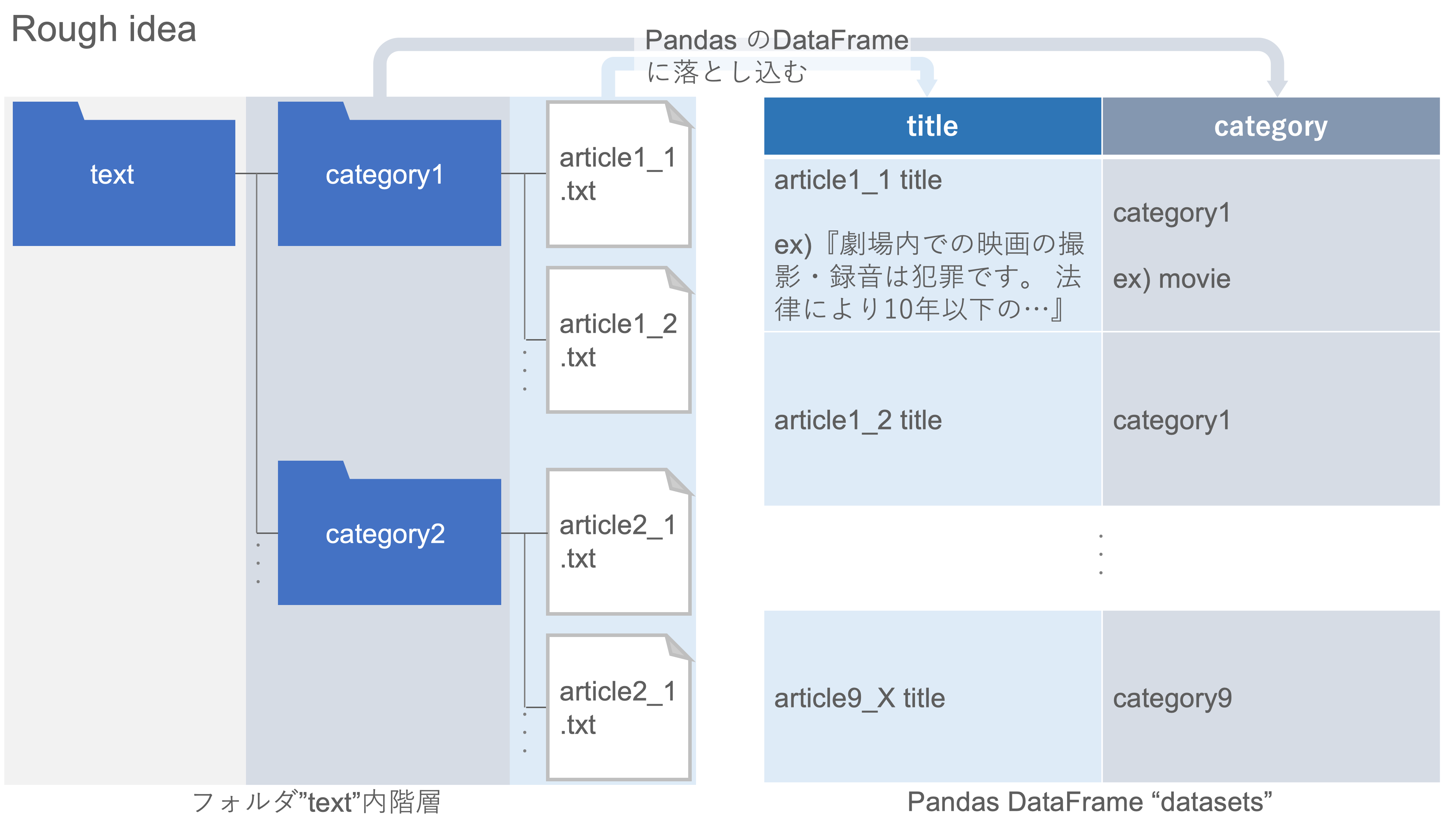
以下の図のように、ダウンロードしたlivedoor ニュースコーパスのテキストデータ[5](フォルダ名"text")をpandasのデータフレームに落とし込みます。説明変数となる文章(今回は冒頭3行のみ)と目的変数となるカテゴリーをそれぞれリストにしていきます。
コードは以下となります。
In[1]
import os
from glob import glob
import pandas as pd
import linecache
categories = [name for name in os.listdir('text') if os.path.isdir("text/" +name)]
print(categories)
datasets = pd.DataFrame(columns=["title", "category"])
for cat in categories:
path = "text/" + cat + "/*.txt"
files = glob(path)
for text_name in files:
title = linecache.getline(text_name, 3)
s = pd.Series([title, cat], index=datasets.columns)
datasets = datasets.append(s, ignore_index=True)
['movie-enter', 'it-life-hack', 'kaden-channel', 'topic-news', 'livedoor-homme', 'peachy', 'sports-watch', 'dokujo-tsushin', 'smax']
- リスト内包表記で text フォルダ内の1層目のフォルダ名を取り出す(ifは重複を防ぐ)。
抜き出したカテゴリー名をまとめたリストを categories とする - カテゴリー名の確認。
- pandasで空のDataFrameである datasets を用意(列名"title"、"category")
- line6で取り出した9つのカテゴリーを変数 cat に入れてループさせる:
- cat を文字列"text/"と文字列"/*.txtで挟んで 変数path に入れる
- 各カテゴリーフォルダに入っている全ての記事ファイルのパスを glob(上位階層フォルダパス) を使ってリスト files に入れる
ここでglob()のワイルドカード"*"には任意の文字列(今回の場合は記事番号)が入る
ex)"text/dokujo-tsushin/dokujo-tsushin-4778030.txt" - line12のfilesに入っているパスを変数 text_name に入れてループさせる:
- linecache.getline(ファイル名,行数)でパスであるtext_name先の".txt"ファイルの内容を抜き出し、変数 title へ入れる
※今回は 行数:3 としており、冒頭3行目までの内容のみを抜き出し、モデルに学習させました - pd.Series([リスト], index=データ指標名)でtitleとcatの1次元配列に変換する(DataFrameに追加できる形にする)
変換したpandas配列を 変数s に入れる - sをdatasetsに追加する
"text"のフォルダ階層構造上、格記事のテキストファイルがカテゴリーフォルダ別に分けられています。そのため、記事を分類するためのカテゴリー名称(目的変数の種類)はカテゴリーフォルダ名とします。カテゴリー名はos.path.isdir(ファイルパス)で取得し、それをpandasのdatasetsの"category"列に追加していきます。
次に説明変数となる記事データを取得します。各記事カテゴリーフォルダ内にある全てのテキストファイルのパスを glob で取得します。取得したパスを一つずつ linecache.getline に入れ、".txt"ファイルの冒頭3行を取得し、datasetsの"title"列に追加していきます。
これで、データセットの準備が完了です。
3.LSTMの実装
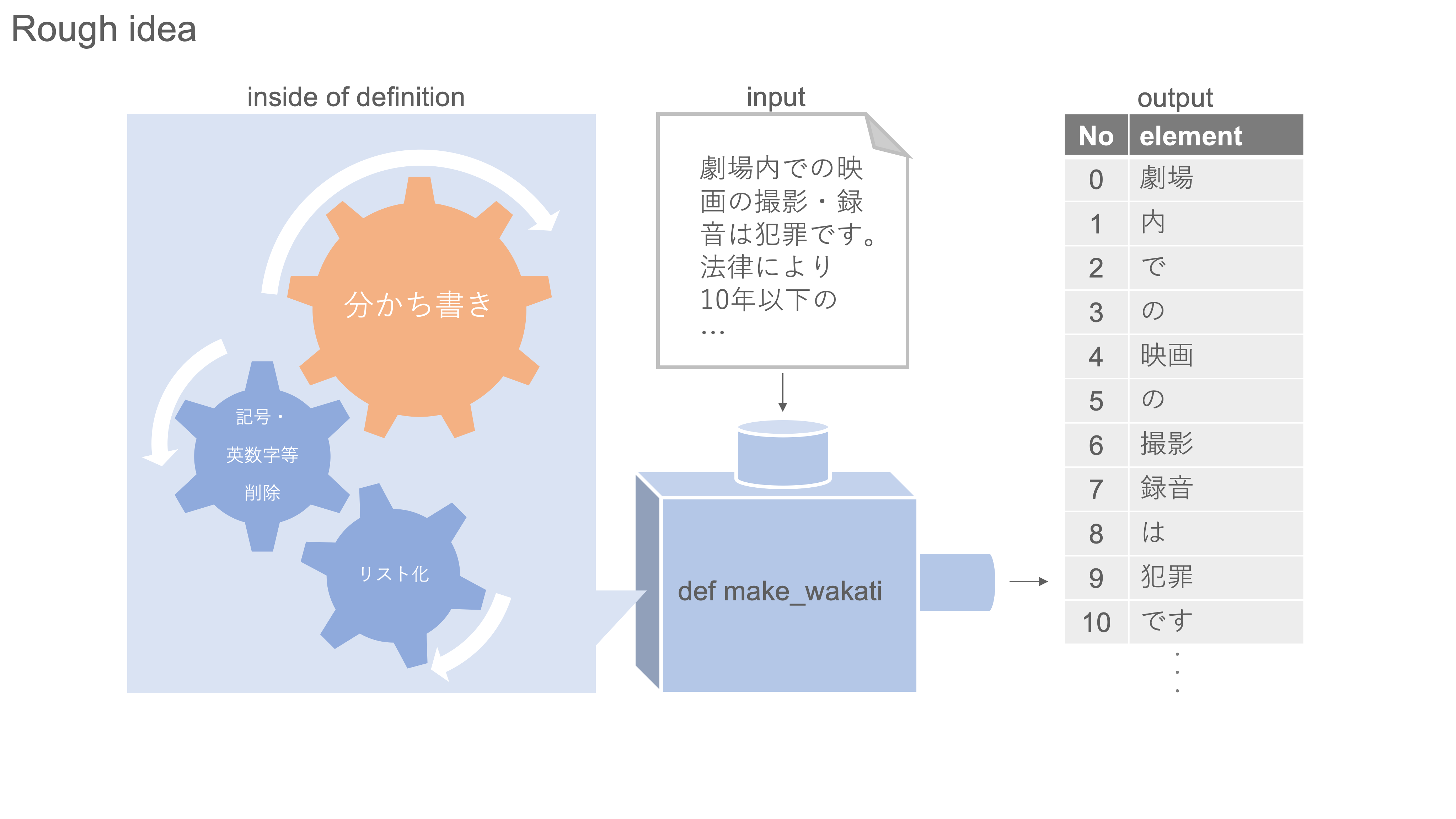
モデルが自然言語を理解・処理するために、品詞レベル(最小単位)で文章を分割します(形態素解析[6])。そのために、入力した文章をバラバラ(分かち書き)にして返してくれる関数"make_wakati"をMeCabライブラリーを使って作成します。
In[2]
import MeCab
import time
In[3]
import MeCab
import re
tagger = MeCab.Tagger("-Owakati")
def make_wakati(sentence):
sentence = tagger.parse(sentence)
sentence = re.sub(r'[0-90-9a-zA-Za-zA-Z]+', " ", sentence)
sentence = re.sub(r'[\._-―─!@#$%^&\-‐|\\*\“()_■×+α※÷⇒—●★☆〇◎◆▼◇△□(:〜~+=)/*&^%$#@!~`){}[]…\[\]\"\'\”\’:;<>?<>〔〕〈〉?、。・,\./『』【】「」→←○《》≪≫\n\u3000]+', "", sentence)
wakati = sentence.split(" ")
wakati = list(filter(("").__ne__, wakati))
return wakati
- MeCab.Tagger(解析形式) を使うことができるインスタンス tagger を生成する
分かち書きをするため、(-Owakati)を利用する
- テキスト sentence を受け取って、分かち書きリストにして返す関数 make_wakati を作成する:
- sentenceをtaggerで分かち書きにする
- 正規表現を利用してsentenceから英数字を削除
- 正規表現を利用してsentenceから特殊文字を削除
- split(分割する文字) メソッドを使って、sentenceをスペース" "で分割したリストを wakatiに入れる
- wakatiから空要素""を取り除いて、文字のみのリストにする
- wakatiを返す
*"MeCab"インポートの重複失礼しました。
MeCab.Tagger()の引数である"-Owakati"は、渡された文章を分かち書きにしてくれます。
ex) "すもももももももものうち"→"すもも も もも も もも の うち"
また、"make_wakati"内では特殊文字の削除も行っております。
『こんにちは』や『Hello』などの語句そのままをモデルへ入力することはできないので、モデルが理解できる形式(単語ベクトル)に変換する必要があります(単語埋め込み[7])。語句からベクトルへの変換は Pytorch の nn.Embedding(①num_embeddings(語句数), ②embedding_dim(語句を数値表現するための次元数)) を利用します。
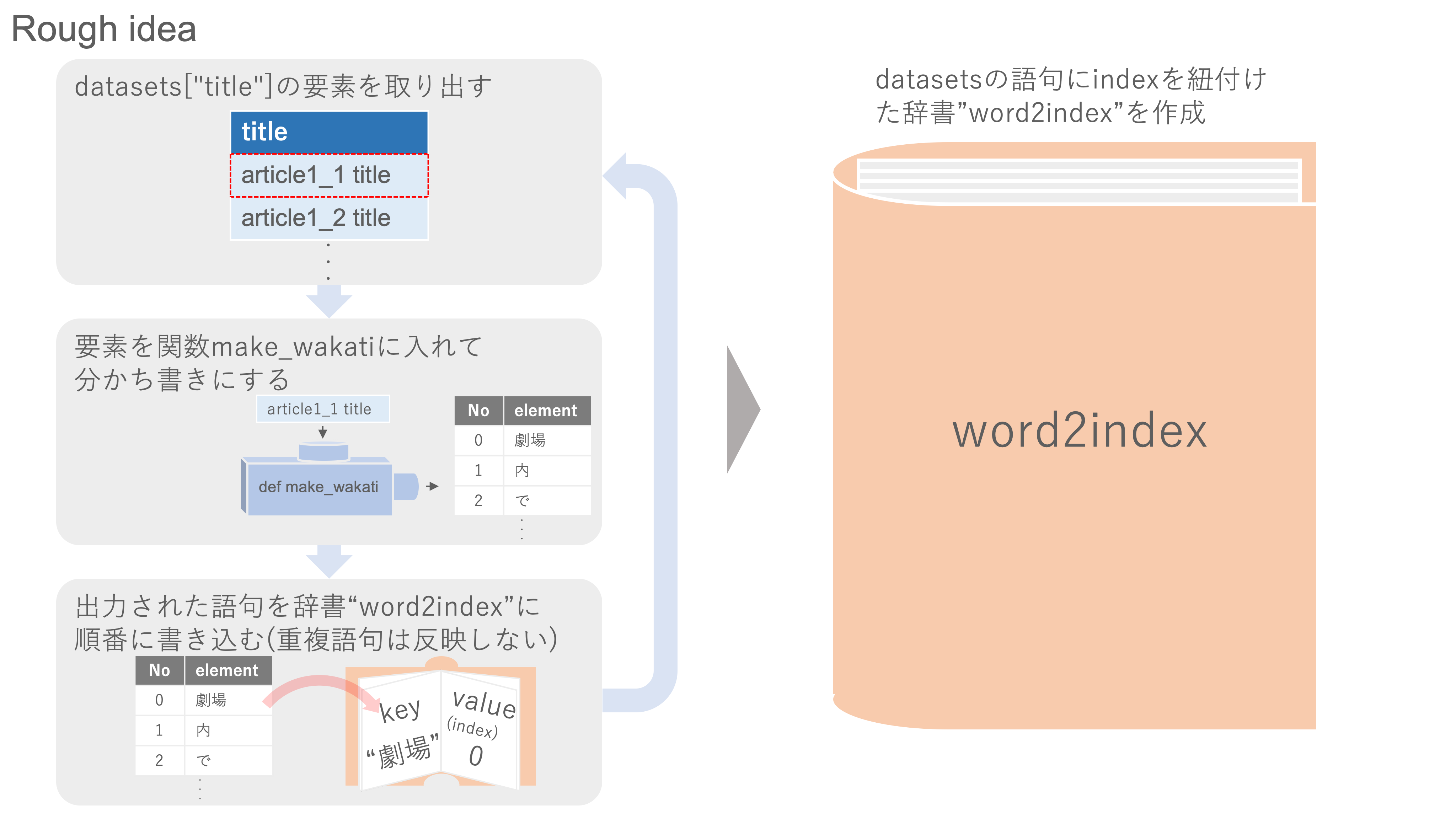
①はモデルを訓練するためのデータの総語句数であり、語句の重複に注意します(同じ格助詞『を』でも異なるベクトルで表現してしまうため、モデルが違う語句と勘違いすることを防ぐ必要があります)。
そのため、語句の重複を取り除き、datasetsの全ての語句を網羅する辞書"word2index"を作成することで、総語句数を調べます(辞書に語句(key)と通し番号のID(value)を書き込むことで、IDの最大値が単語数となります)。
②については任意で設定・調整できますので、ひとまず放っておきます。
In[4]
word2index = {}
# 系列を揃えるためのパディング文字列を追加
# パディング文字列のIDは0とする
word2index.update({"":0})
for title in datasets["title"]:
wakati = make_wakati(title)
for word in wakati:
if word in word2index: continue
word2index[word] = len(word2index)
print("vocab size : ", len(word2index))
vocab size : 12944
- 辞書 word2index を準備する
- # 系列を揃えるためのパディング文字列を追加
- # パディング文字列のIDは0とする
- Line2,3 コメントの通りキー"<pad>"のバリューは 0 とする
- In[1]で作成したdatasetsの"title"列要素を変数 title に入れてループさせる:
- In[2]で作成したmake_wakatiでtitleを分かち書きにし、リスト wakatiに入れる
- wakatiの単語を変数 wordに入れてループさせる:
- 辞書word2indexにwordが既に登録されていたら、Line8に戻り、次の単語で進める
- word2indexに単語(キー)とID(バリュー)を登録する
- word2indexに登録された単語数を確認
In[3]で作成した関数"make_wakati"へDatasetsの"title"要素を一つずつ入れて、出力された語句を"word2index"に書き込みます(書き込み時に重複を調べます)。全ての"title"要素を処理したら"word2index"の完成です。
次に以下を行いました。
- 関数"sentence2index"、"category2index"の作成(line5~15)
- 訓練データと検証データの分割(line17~39)
- データをバッチでまとめる関数train2batchの作成(line41~49)
In[5]
from sklearn.model_selection import train_test_split
import random
from sklearn.utils import shuffle
cat2index = {}
for cat in categories:
if cat in cat2index: continue
cat2index[cat] = len(cat2index)
def sentence2index(sentence):
wakati = make_wakati(sentence)
return [word2index[w] for w in wakati]
def category2index(cat):
return [cat2index[cat]]
index_datasets_title_tmp = []
index_datasets_category = []
# 系列の長さの最大値を取得。この長さに他の系列の長さをあわせる
max_len = 0
for title, category in zip(datasets["title"], datasets["category"]):
index_title = sentence2index(title)
index_category = category2index(category)
index_datasets_title_tmp.append(index_title)
index_datasets_category.append(index_category)
if max_len < len(index_title):
max_len = len(index_title)
# 系列の長さを揃えるために短い系列にパディングを追加
# 後ろパディングだと正しく学習できなかったので、前パディング
index_datasets_title = []
for title in index_datasets_title_tmp:
for i in range(max_len - len(title)):
title.insert(0, 0) # 前パディング
# title.append(0) # 後ろパディング
index_datasets_title.append(title)
train_x, test_x, train_y, test_y = train_test_split(index_datasets_title, index_datasets_category, train_size=0.7)
# データをバッチでまとめるための関数
def train2batch(title, category, batch_size=100):
title_batch = []
category_batch = []
title_shuffle, category_shuffle = shuffle(title, category)
for i in range(0, len(title), batch_size):
title_batch.append(title_shuffle[i:i+batch_size])
category_batch.append(category_shuffle[i:i+batch_size])
return title_batch, category_batch
- 辞書 cat2index を準備する
- In[1]line6のcategoriesの要素を変数 cat に入れてループさせる:
- cat2indexにcatが既に登録されていたら、line6に戻り、次のカテゴリーで進める
- cat2indexにカテゴリー名(キー)とカテゴリーID(バリュー)を登録する
- テキスト sentence を受け取り、sentenceの単語を単語ID(word2indexの)に変換して返す関数をつくる:
- sentenceをmake_wakatiで分かち書きリストに変換し、リスト wakati に入れる
- リスト内包表記でwakatiの単語を単語ID(word2indexの)に変換して返す
- リスト cat を受け取り、catのカテゴリーをカテゴリーID(cat2indexの)に変換して返す関数をつくる:
- リスト内包表記でcatのカテゴリーID(cat2indexの)に変換して返す
- リスト index_datasets_title_tmp を準備する
- リスト index_datasets_category を準備する
- # 系列の長さの最大値を取得。この長さに他の系列の長さをあわせる
- 変数 max_len を初期値0で準備する
- datasetsの"title"列、"category"列の要素を、それぞれ変数 title, category に入れてループさせる:
- line10~19で作成したsentence2indexにtitleを入れて、文章を分かち書きリスト化・単語IDに変換し、変数 index_title に入れる
- line14~15で作成したcategory2indexにcategoryを入れて、カテゴリーIDに変換し、変数 index_category に入れる
- index_datasets_title_tmpへindex_titleを追加する
- index_datasets_categoryへindex_categoryを追加する
- 文章を分かち書きしたindex_titleの要素数を調べて、max_lenより大きいか調べる:
- index_titleの要素数がmax_lenより大きいならば、max_lenをindex_titleの要素数に更新する
- # 系列の長さを揃えるために短い系列にパディングを追加
- # 後ろパディングだと正しく学習できなかったので、前パディング
- リスト index_datasets_title を準備する
- index_datasets_title_tmpの要素を title に入れてループさせる:
- max_len と titleの要素数 の差を変数 i に入れてループさせる:
- titleにinsert(位置,列名)で前からi分だけ"<pad>"を入れていく(パディングする)
今回は前からパディングするので、第一引数が0、"<pad>"の単語IDが0なので第二引数も0とする - # title.append(0) # 後ろパディング
- index_datasets_titleへパディング処理したtitleを追加する
- train_test_splitで、index_datasets_titleを説明変数、index_datasets_categoryを目的変数とし、 訓練データ:検証データ=7:3 で分割する
- # データをバッチでまとめるための関数
- title(訓練データ)、category(検証データ)を受け取り、バッチサイズ100ずつにまとめて返す関数をつくる:
- リスト title_batch を準備する
- リスト category_batch を準備する
- shuffle(リスト)でtitle、categoryの順番をランダムに並べ替え、それぞれtitle_shuffle、category_shufleへ入れる
- batchサイズ100刻みでループさせる:
- title_batchに100個のtitle_shuffleデータを1つの要素として入れる
- category_batchに100個のcategory_shuffleデータを1つの要素として入れる
- title_batch、category_batchを返す
①について、In[3]の関数"make_wakati"を使った文章中の語句をID化する関数が"sentence2index"、カテゴリー名称を受けとってカテゴリーIDをリスト型で返す関数が"category2index"です。
②について、お馴染みのscikit-learnのtrain_test_splitです。訓練データ:検証データを7:3にしました。
③について、batch_size=100 刻みでfor-loopを回し、スライス(ex) a[start:step:step])を利用して入力されたデータを100データ単位でまとめました。
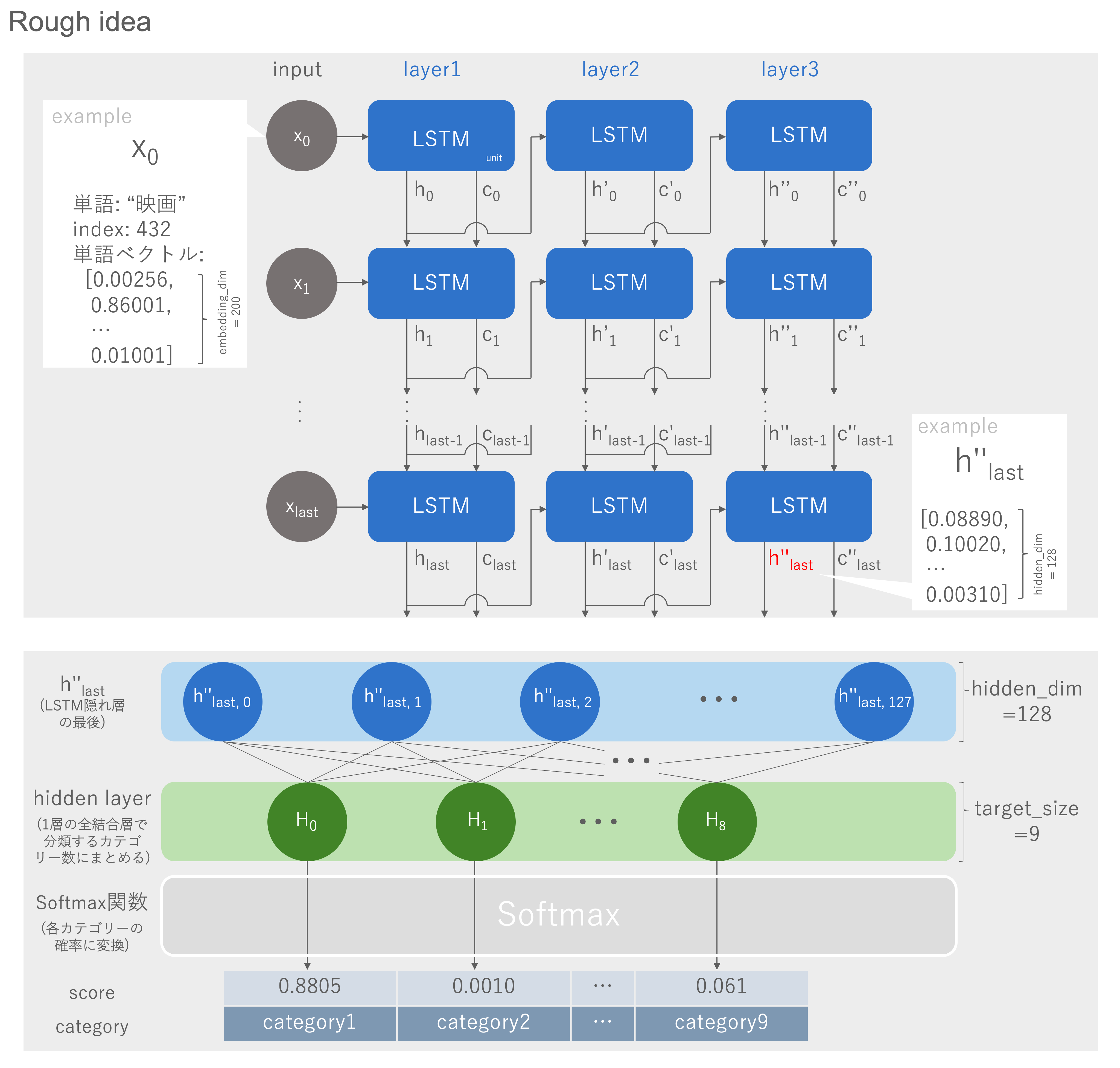
LSTMのモデルを作成していきます。LSTMの構造や特徴は、教科書や他サイトでも分かり易い解説が溢れているので、割愛します。 本講座をパスする条件として深層学習(中間層3層以上)だったので、以下図のようなモデルを目指しました。In[5]のsentence2indexにより単語ID化した文章をベクトルに変換して、1層目のLSTMユニットへ入力します。重ねた層(2層目、3層目)への入力は、前層のそれぞれhとh'となります。分類のために利用する出力は、3層目で最後に出力されたh''lastです。
LSTM隠れ層からの出力hは任意の次元(今回は128次元)を設定し、softmax関数に通して9つのカテゴリーに分類するために、128次元→9次元へ変換する全結合層を噛ませます。最後にsoftmaxから各カテゴリーの確率が算出されてモデルの判定が完了となります。
In[6]
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class LSTMClassifier(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size, layer_number):
super(LSTMClassifier, self).__init__()
self.hidden_dim = hidden_dim
# の単語IDが0なので、padding_idx=0としている
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim, padding_idx=0)
# batch_first=Trueが大事!
self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_dim, num_layers=layer_number, batch_first=True)
self.hidden2tag = nn.Linear(hidden_dim, tagset_size)
self.softmax = nn.LogSoftmax()
def forward(self, sentence):
embeds = self.word_embeddings(sentence)
#embeds.size() = (batch_size × len(sentence) × embedding_dim)
_, lstm_out = self.lstm(embeds)
# lstm_out[0].size() = (1 × batch_size × hidden_dim)
tag_space = self.hidden2tag(lstm_out[0][2])
# tag_space.size() = (1 × batch_size × tagset_size)
# (batch_size × tagset_size)にするためにsqueeze()する
tag_scores = self.softmax(tag_space.squeeze())
# tag_scores.size() = (batch_size × tagset_size)
return tag_scores
EMBEDDING_DIM = 200
HIDDEN_DIM = 128
VOCAB_SIZE = len(word2index)
TAG_SIZE = len(categories)
LAYER_NUMBER = 3
model = LSTMClassifier(EMBEDDING_DIM, HIDDEN_DIM, VOCAB_SIZE, TAG_SIZE, LAYER_NUMBER)
loss_function = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
- クラス LSTMClassifier をつくる:
- embedding_dim(単語ベクトルの次元), hidden_dim(隠れベクトルの次元), vocab_size(語彙数), tagset_size(最終的に取得する次元(今回はカテゴリー数である9)), layer_number(層数)を受け取り初期化する:
- 親クラス(nn.Module)へLSTMClassifierを渡して初期化する
- 隠れベクトルの次元(htを表現する次元)を定義
- # の単語IDが0なので、padding_idx=0としている
- nn.Embedding(単語サイズ, 単語ベクトルの次元, パディングとして処理する値)で単語ベクトル変換するメソッドを設定
- # batch_first=Trueが大事!
- nn.LSTM(インプットサイズ(単語ベクトル次元),隠れベクトルの次元、層数, batch化)でLSTMモデルを設定
- nn.Linear(インプット(h''last), アウトプット(カテゴリー数))
- ソフトマックス関数の設定
- sentenceを受け取って、順伝播させるメソッドを設定:
- line11のword_embeddingでsentenceを単語ベクトル化し、embedsに入れる
- #embeds.size() = (batch_size × len(sentence) × embedding_dim)
- lstmにembedsを入れて、出力 htとctのを lstm_out に入れる
- # lstm_out[0].size() = (1 × batch_size × hidden_dim)
- lstm_out から3層目のhlastを取り出し、hidden2tagに入れて128次元→9次元へ減らしtag_space に入れる
- # tag_space.size() = (1 × batch_size × tagset_size)
- # (batch_size × tagset_size)にするためにsqueeze()する
- tag_spaceをsoftmaxに入れて、各カテゴリーの確率を算出する(tag_scoresが計算結果)
- # tag_scores.size() = (batch_size × tagset_size)
- tag_scoresを返す
- 埋め込み次元(単語ベクトルの次元)を設定(今回は200)
- 隠れベクトルの次元を設定(今回は128)
- word2indexの語彙数をVOCAB_SIZEに入れる
- カテゴリー数をTAG_SIZEに入れる
- LSTMの層数(今回は3)をLAYER_NUMBERに入れる
- EMBEDDING_DIM, HIDDEN_DIM, VOCAB_SIZE, TAG_SIZE, LAYER_NUMBERをLSTMCLassifierへ入れてmodelとする
- 損失関数を設定(LogSoftmaxのため)
- 最適化手法としてAdamを採用
EMBEDDING_DIM(埋め込み次元)とHIDDEN_DIM(隠れベクトルの次元)、loss_function(損失関数)、optimizer(最適化手法)は、参考した記事と同じに設定しました。調整すると精度が上がると思います。
以上でLSTMに学習させる準備が整ったので、以下コードの通り、訓練データで学習→検証データで精度を確認 を20回繰り返してLSTMの実装を終了しました。
In[7]
lstm_train_accuracy_list = []
lstm_test_accuracy_list = []
maxepoch = 20
for epoch in range(maxepoch):
start_time = time.process_time()
temp_train_acc = 0
train_loss = 0
train_acc = 0
title_batch, category_batch = train2batch(train_x, train_y)
for i in range(len(title_batch)):
batch_loss = 0
model.zero_grad()
title_tensor = torch.tensor(title_batch[i])
# category_tensor.size() = (batch_size × 1)なので、squeeze()
category_tensor = torch.tensor(category_batch[i]).squeeze()
out = model(title_tensor)
batch_loss = loss_function(out, category_tensor)
_, preds = torch.max(out, 1)
batch_loss.backward()
optimizer.step()
train_loss += batch_loss.item()
temp_train_acc += torch.sum(preds==category_tensor).item()
train_acc = temp_train_acc / (len(title_batch)*100)
temp_test_acc = 0
test_loss = 0
test_acc = 0
with torch.no_grad():
title_batch, category_batch = train2batch(test_x, test_y)
for i in range(len(title_batch)):
title_tensor = torch.tensor(title_batch[i])
category_tensor = torch.tensor(category_batch[i]).squeeze()
out = model(title_tensor)
batch_loss=loss_function(out, category_tensor)
_, preds = torch.max(out, 1)
test_loss += batch_loss.item()
temp_test_acc += torch.sum(preds==category_tensor).item()
test_acc = temp_test_acc / (len(title_batch)*100)
print("epoch", epoch, "\t" , "train loss: ", round(train_loss, 5), "\t" , "train acc: ", round(train_acc, 5), "\t" , "test loss:", round(test_loss, 5), "\t" , "test acc:", round(test_acc, 5))
lstm_train_accuracy_list.append(train_acc)
lstm_test_accuracy_list.append(test_acc)
end_time = time.process_time()
elapsed_time = end_time - start_time
print("process time: ", round(elapsed_time, 0), "[s]")
print("done.")
epoch 0 train loss: 101.45796 train acc: 0.28654 test loss: 36.7009 test acc: 0.41739
process time: 19.0 [s]
epoch 1 train loss: 64.87202 train acc: 0.56288 test loss: 27.30444 test acc: 0.56826
process time: 18.0 [s]
・・・
- リスト lstm_train_accuracy_list を準備する(のちほどグラフプロットに使う学習時の正解率データを取っておくため)
- リスト lstm_test_accuracy_list を準備する(のちほどグラフプロットに使う検証時の正解率データを取っておくため)
- エポック数を設定する
- line4のエポック数分(今回は20回)だけループさせる:
- 1エポックあたりの処理時間を計測するため、time.process_time()でストップウォッチを作動
- 学習時の正解数を入れておく変数 temp_train_acc を用意(初期設定)
- 学習時の損失を入れておく変数 temp_loss を用意(初期設定)
- 学習時の正解率を入れておく変数 train_acc を用意(初期設定)
- 学習データ train_x, train_y(In[5]line39)をIn[5]のline42~49のtrain2batchでバッチ単位にまとめ、それぞれtitle_batch、category_batchとする
- 学習データバッチの数だけループさせる:
- バッチ単位の損失を入れる変数 batch_loss を準備する(各バッチの損失をline20でtrain_lossに足していく)
- モデルの勾配をリセット
- title_batchをPyTorchで扱えるTensor型に変換する
- # category_tensor.size() = (batch_size × 1)なので、squeeze()
- category_batchをPyTorchで扱えるTensor型に変換する
- model(LSMT)にtitle_batchを入力して、記事の各カテゴリーの確率を出力させる
- line21の分類結果とcategory_batchを損失関数(In[6]line37)に渡して損失を計算する
- torch.max()に判定結果を入力して確率が最も高いカテゴリーを判定結果として変数 predsに入れておく(line30で正解率を出すため)
※torch.max()は ①最大値, ②最大値の要素位置 = torch.max(x) となるので①は_で棄却する - line23の損失を逆伝播させる
- 最適化手法(今回はAdam)を使ってパラメータを更新する
- 発生した損失(batch_loss)をtrain_lossに積み重ねる
- preds(モデルの判定結果)をcategory_batch(目的変数)で採点して、temp_train_accにモデルの判定正解数を積み重ねる
- モデルの正解率を出す(正解した数 / 学習に用いたデータ数)
- 検証時の正解数を入れておく変数 temp_test_acc を用意(初期設定)
- 検証時の損失を入れておく変数 test_loss を用意(初期設定)
- 検証時の正解率を入れておく変数 test_acc を用意(初期設定)
- 検証なのでTensorの勾配計算をしないようにする:
- 検証データtext_x、test_yをtrain2batchでバッチ単位にまとめ、それぞれtitle_batch、category_batchとする
- 検証データバッチの数だけループさせる:
- title_batchをPyTorchで扱えるTensor型に変換する
- category_batchをPyTorchで扱えるTensor型に変換する
- 学習済みのmodel(LSMT)にtest_batchを入力して、記事の各カテゴリーの確率を出力させる
- line42の分類結果とcategory_tensorを損失関数(In[6]line37)に渡して損失を計算する
- torch.max()に判定結果を入力して確率が最も高いカテゴリーを判定結果として変数 predsに入れておく(line48で正解率を出すため)
- 発生した損失(batch_loss)をtest_lossに積み重ねる
- preds(モデルの判定結果)をcategory_tensor(目的変数)で採点して、temp_test_accにモデルの判定正解数を積み重ねる
- モデルの正解率を出す(正解した数 / 学習に用いたデータ数)
- エポック数、損失(学習)、正解率(学習)、損失(検証)、正解率(検証)を確認
- lstm_train_accuracy_listにtrain_accを追加する
- lstm_test_accuracy_listにtest_accを追加する
- time.process_time()でストップウォッチを止める
- 1エポックあたりの処理時間を計測するため、line6のstart_timeとline54のend_timeの差をとる
- 1エポックあたりの処理時間を確認する
- 全部終わったら"done."を表示
作成したモデルの考察は、『CODE』ページに記載した通りです。学習の推移は以下となります。
グラフの作成については、pyplotを利用しました。
In[8]
import matplotlib.pyplot as plt
plt.plot(range(maxepoch), lstm_train_accuracy_list)
plt.plot(range(maxepoch), lstm_test_accuracy_list)
plt.legend(["Train_accuracy", "Test_accuracy"])
plt.xlabel("#epoch")
plt.ylabel("Accuracy")
plt.show()
- 各エポック毎の学習時の正解率をプロットする
- 各エポック毎の検証時の正解率をプロットする
- グラフに凡例(lstm_train_accuracy_list と lstm_test_accuracy_list)を載せる
- 横軸名『#epoch』を載せる
- 縦軸名『Accuracy』を載せる
- グラフを表示
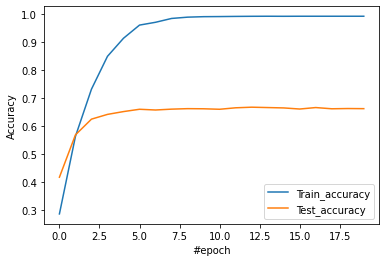
モデルの精度を高めることが課題ではない(と理解しました)ので、正解率向上の改善活動は行いませんでした。
4.CNNのデータセットの準備
CNNモデルを学習させるためのデータセットを準備します。LSTMで加工したものを使えたらスマートだったのですが、力及ばず、CNN用に加工しました。
記事データは3行目からが本文となっていたので、3行目以降の文章(文字列)をリスト "text" に入れました。カテゴリー名は、LSTM同様にリスト category に入れました。そして、"text"、categoryをpandas のDataFrame化して準備が完了です。
In[9]
from pathlib import Path
import pandas as pd
In[10]
paths = list(Path('text').iterdir())
labels = []
texts = []
for path in paths:
for filepath in path.glob('*.txt'):
if not filepath.name == 'LICENSE.txt':
with open(filepath) as f:
next(f)
next(f)
text = f.read().replace('\u3000','').replace('\n','')
texts.append(text)
labels.append(path.name)
- text フォルダ内のフォルダパスを取得して、リストとしてpathsに入れる
- リスト labels を準備する
- リスト texts を準備する
- pathsの要素を path に入れてループさせる:
- pathのフォルダ( ex)movie )内に入っている ".txt" ファイルへのパスを filepath に入れてループさせる:
- filepathが"LICENSE.txt"以外ならば、以下の処理を進める
※"LICENSE.txt"には、CCライセンス情報が入っており、記事ではありません
- filepathのファイルを開く(終わったら閉じる)
- 開いたテキストファイルの2行目(日付情報)へ移動
- 開いたテキストファイルの3行目(本文始まり)へ移動
- 開いたテキストファイルの3行目以降の文字列を、改行などを取り除き、変数 text に入れる
- リストtextsに変数textの内容を要素として追加
- リストlabelsに変数textのカテゴリーを要素として追加
(2. LSTMのデータセットの準備の通り、text内のファイル階層的に変数pathがカテゴリー名となるので、そのままpathの内容であるカテゴリーフォルダ名を入れます)
In[11]
news_df = pd.DataFrame({
'body': texts,
'category': labels
})
In[10]line11で全角空白"\u3000"と改行"\n"を取り除いています。LSTMでは特殊文字も取り除いているので、こちらも合わせた方が良かったと(今更ですが)思います。
5.CNNの実装
CNNは、参考記事のコードとほとんど同じです[3]。 大変わかりやすく、勉強になる記事ですので、そちらをご確認いただければと思います。
6.LSTMとCNNの性能比較
最後にLSTMとCNNの性能を比較します。
In[19]
import matplotlib.pyplot as plt
plt.plot(range(maxepoch), lstm_test_accuracy_list)
plt.plot(range(maxepoch), cnn_test_accuracy_list)
plt.legend(["LSTM", "CNN"])
plt.xlabel("#epoch")
plt.ylabel("Accuracy")
plt.show()
- 各エポック毎のLSTMモデルでの正解率をプロットする(検証データ)
- 各エポック毎のCNNモデルでの正解率をプロットする(検証データ)
- グラフに凡例(LSTM と CNN)を載せる
- 横軸名『#epoch』を載せる
- 縦軸名『Accuracy』を載せる
- グラフを表示
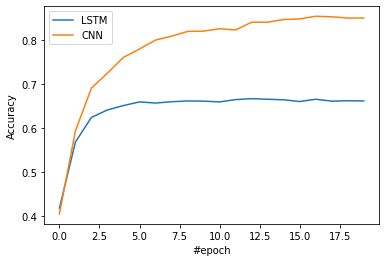
冒頭の注意書きの通り、どちらのモデルも性能を改善することをしておりませんので、今回の比較結果に意味はないのですが、CNNの方が高い正解率となりました。
コメント・お問合せ
以下のツイートの『返信』にてお願いいたします